Wissen im Web als Hirnersatz
Man kann sich doch nicht alles merken!
Deshalb wird hier alles notiert.
Apache auf macOS
Allerdings wird die Config durch die System Integrity Protection beim nächsten Reboot oder spätestens Update wieder zurück gesetzt…
Apache ist schon lange mit dabei, bloß irgendwann ist in den System Preferences das Häkchen zum einschalten verschwunden.
Ab ins Terminal, es reicht ein:
sudo apachectl start
stop, restart und configtest sind auch hilfreich!
Unter http://localhost sollte nun der
It works! Text stehen.
- DocumentRoot:
/Library/WebServer/Documents/ - UserLevelRoot:
/Users/User/Sites
User-Directories
Für die User-Directories muss man noch ein bisschen basteln:
Es braucht erst einen Sites Ordner:
mkdir /Users/User/Sites
Dann eine /etc/apache2/users/user.conf erstellen:
<Directory "/Users/User/Sites/">
AllowOverride All
Options Indexes MultiViews FollowSymLinks
Require all granted
</Directory>
Und in der /etc/apache2/httpd.conf noch ein paar Module einschalten,
sowie die extra/httpd-userdir.conf einbinden lassen:
LoadModule authz_core_module libexec/apache2/mod_authz_core.so
LoadModule authz_host_module libexec/apache2/mod_authz_host.so
LoadModule userdir_module libexec/apache2/mod_userdir.so
LoadModule include_module libexec/apache2/mod_include.so
LoadModule rewrite_module libexec/apache2/mod_rewrite.so
Include /private/etc/apache2/extra/httpd-userdir.conf
Ab High Sierra braucht man noch ein bisschen mehr
sonst rennt man in einen 403 Forbidden Fehler:
LoadModule vhost_alias_module libexec/apache2/mod_vhost_alias.so
Include /private/etc/apache2/extra/httpd-vhosts.conf
Damit die oben erstellte user.conf geladen wird,
in der /etc/apache2/extra/httpd-userdir.conf den Kommentar
von dieser Zeile entfernen:
Include /private/etc/apache2/users/*.conf
Fertig! Nach einem apachectl restart sieht man nun unter
http://localhost/~user
den Inhalt von /Users/User/Sites.
PHP and Dynamite
Man kommt leider immer noch nicht drum rum, manchmal braucht man wirklich noch PHP..
Kommt in ganz moderner 5er Version, seit kurzem sogar als 7er..
In der /etc/apache2/httpd.conf muss man dazu den Kommentar
von dieser Zeile entfernen:
LoadModule php5_module libexec/apache2/libphp5.so
bzw:
LoadModule php7_module libexec/apache2/libphp7.so
apachectl restart, und schon sollte eine info.php funktionieren:
<?php phpinfo(); ?>
Bluetooth Audio Settings
defaults read com.apple.BluetoothAudioAgent
Domain com.apple.BluetoothAudioAgent does not exist
Ich habe einen kleinen Knubbel: Vorne kommt Strom und Bluetooth rein, hinten kommt Musik raus..
Die Default-Settings in macOS sind so schlecht, dass meist nur Musik mit Knistern und Rauschen ankommt.. Schämt euch!
Bei der Suche nach einer Lösung stößt man auf diese Anleitung um das zu fixen, reicht aber noch nicht ganz..
Erstmal alle Werte auslesen:
defaults read com.apple.BluetoothAudioAgent
Lösung: Man muss die Regler auf Elf drehen!
Hier meine Settings, die ich nach langem Feilen rausgefunden habe, und die für mich funktionieren:
defaults write com.apple.BluetoothAudioAgent "Apple Bitpool Max (editable)" 80
defaults write com.apple.BluetoothAudioAgent "Apple Bitpool Min (editable)" 58
defaults write com.apple.BluetoothAudioAgent "Apple Initial Bitpool (editable)" 40
defaults write com.apple.BluetoothAudioAgent "Negotiated Bitpool" 58
defaults write com.apple.BluetoothAudioAgent "Negotiated Bitpool Max" 58
defaults write com.apple.BluetoothAudioAgent "Negotiated Bitpool Min" 48
Zum Ändern der Werte sollte man Bluetooth ausschalten, alle Programme die was mit Sound machen beenden, und erst dann im Terminal die Werte ändern.
Danach kann ein Neustart nicht schaden, oder sowas hier:
sudo killall bluetoothaudiod
# sudo killall coreaudiod
Geektool Skripte
Der Artikel ist historisch.
Geektool ist ein feines Programm. Lässt sich viel mit machen.
Hier eine Ansammlung diverser Skripte. Nicht alles habe ich in Verwendung, also keine Garantie, dass auch alles so tut, wie es soll:
System:
top -l 1 | \
grep -E "CPU usage|Load Avg|PhysMem"
Dateisystem:
df -h | \
sed -e '/disk/b' -e d | \
awk '{print $3 "/" $2, "==", $5, "(" $4 ")", $9}'
Externe v4-Adresse:
curl -f -s http://checkip.dyndns.org/ | \
sed 's/[a-zA-Z<>/ :]//g'
Offene Verbindungen:
netstat -ab -f inet | \
grep -i established | \
awk '{print $4, $5, "(" $1 ")"}'
Headlines aus einem RSS-Feed:
curl -f -s http://blog.fefe.de/rss.xml | \
sed -n 's:.*<title>\(.*\)</title>.*:\1:p' | \
sed '/^$/d'
Ganz interessant sind Log-Watcher für:
/private/var/log/system.log/private/var/log/appfirewall.log/private/var/log/wifi.log
Weiterhin sei auf die API vom Norwegischen Wetterdienst verwiesen, mit der sich so manches basteln lässt..
Jabber Settings in iChat
Jabber bzw. XMPP ist inzwischen komplett aus Messages geflogen.
iChat wurde zwar in Messages umbenannt, unter der Haube heißt alles noch iChat.. Ich prangere das an :)
Interessant ist die ~/Library/Preferences/com.apple.iChat.Jabber.plist.
Darin lassen sich ein paar Einstellungen konfiguriern:
- Unter
Root/Accounts/WHATEVER/finden sich z.B. die FelderPrioritysowieResourceName - Auf gewünschte Werte einstellen
- Glücklich sein!
.iso auf USB-Sticks
iso Images vom Mac aus zu pressen ist so eine Sache. Manche Images wollen partout nicht booten, andere aber schon.
Hier ein Weg, bei dem sich die USB-Sticks dann auch so verhalten, wie es das iso Image vorsieht:
- Image von
.isonach.dmgkonvertieren:
hdiutil convert -format UDRW -o ~/damage ~/quelle.iso
Die Endung wird automatisch von hdiutil ergänzt (~/damage.dmg).
- Double check
diskutil list
Es werden alle vorhandenen Speichermedien gelistet, beispielsweise ist der
USB-Stick unter /dev/disk4 zu finden.
Bitte hier besonders Acht geben, und nicht versehentlich das falsche Device erwischen!
Wie immer gilt: Kein Backup - kein Mitleid!
- USB-Stick aushängen:
diskutil unmountDisk /dev/disk4
- Image pressen:
sudo dd if=~/damage.dmg of=/dev/rdisk4 bs=1m conv=sync
Was, /dev/rdisk4?!
Ist ein sog. Character Device, kein Block Device,
es werden keine Puffer benutzt, und ist somit u.U. etwas schneller.
- USB-Stick auswerfen:
diskutil eject /dev/disk4
macOS Bootstick
Um sich einen Bootstick für Mac OS X zu erstellen, lädt man zunächst das gewünschte Release aus dem AppStore herunter.
Wird der AppStore in einem Gast-Account betrieben,
kann dieser nicht nach ~/Applications schreiben.
Er frägt zwar nach einem Passwort, dieses wird aber ignoriert und es werden brav gigabyteweise Daten runtergeladen, und er bricht am letzten Schritt ab.
Abhilfe schafft hier resetpasswort auf der Recovery-Console.
Der USB-Stick darf natürlich nicht zu klein sein, und im Beispiel ist dieser
unter /Volumes/Stift gemountet.
Ist der Download fertig, kann man den Stick beschreiben lassen:
cd /Applications/Install\ macOS\ High\ Sierra.app/Contents/Resources
sudo ./createinstallmedia \
--volume /Volumes/Stift \
--applicationpath /Applications/Install\ macOS\ High\ Sierra.app \
--nointeraction
Ab 10.14 (Mojave) gibt es keinen --applicationpath mehr.
Dafür aber --downloadassets. Deshalb:
cd /Applications/Install\ macOS\ Monterey.app/Contents/Resources
sudo ./createinstallmedia \
--volume /Volumes/Stift \
--nointeraction \
--downloadassets
- Warten…
- Neu starten
altbeim booten gedrückt halten- USB-Stick auswählen
- …
- Profit!
path_helper
Wie kommt unter macOS eigentlich der $PATH zustande?
Die /etc/profile führt beim Start den path_helper aus:
cat /etc/profile
# System-wide .profile for sh(1)
if [ -x /usr/libexec/path_helper ]; then
eval `/usr/libexec/path_helper -s`
fi
…
man path_helper spricht folgendes:
$PATHwird zusammengesetzt aus folgenden Dateien:/etc/pathsund alles unter/etc/paths.d/
- Eine Zeile == ein Ordner
- “… should not be invoked directly”
- “It is intended only for use by the shell profile.”
Also: Dort ansetzen:
echo "/Users/user/bin" > /etc/paths.d/user
Schaut dann so aus:
ls /etc/paths.d
MacGPG2 TeX user
cat /etc/paths.d/*
/usr/local/MacGPG2/bin
/Library/TeX/texbin
/Users/user/bin
cat /etc/paths
/usr/local/bin
/usr/bin
/bin
/usr/sbin
/sbin
Funktioniert für alle Shells.
Obacht: /Users/user/bin gilt dann für alle Benutzer.
Der Check gibt folgendes:
/usr/libexec/path_helper -s
PATH="/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/Users/user/bin:/Library/TeX/texbin:/usr/local/MacGPG2/bin"; export PATH;
Power Chime
defaults read com.apple.PowerChime
Domain com.apple.PowerChime does not exist
Thinkpads können das, iPhones machen das, und jetzt ist der Mac dran:
Einen Sound abspielen beim anstecken vom Ladegerät.
Das Feature wird so aktiviert:
defaults write com.apple.PowerChime ChimeOnAllHardware -bool true
Danach entweder neustarten (haha), oder den Daemon manuell starten:
open /System/Library/CoreServices/PowerChime.app
Der Sound, der gespielt wird liegt mit im Bundle. Zum hören:
cd /System/Library/CoreServices/PowerChime.app
afplay Contents/Resources/connect_power.aif
Press And Hold
Es scheint aber mittlerweile standardmäßig aktiv zu sein.
Dieses Feature:
Wird so aktiviert:
defaults write -g ApplePressAndHoldEnabled -bool true
Repair Disk Permissions
Tragisch..
Das neue Disk-Utility ist ziemlich minimal geraten.
Das Feature die Disk-Permissions überprüfen und reparieren zu lassen gibt es nicht mehr.
Jedenfalls sind die Knöpfe zum klicken verschwunden, das Dienstprogramm existiert aber weiterhin.
Verify Disk Permissions:
/usr/libexec/repair_packages --verify --standard-pkgs --volume /
Repair Disk Permissions:
/usr/libexec/repair_packages --repair --standard-pkgs --volume /
(run as root)
Autologin
Um den User user automatisch auf der shell einzuloggen,
braucht es ein paar Schritte
In der /etc/gettytab müssen wir ein Teminal definieren:
al.user:\
:al=user:tc=Pc:
Die /etc/ttys bekommt eine Zeile ersetzt. Von:
ttyv0 "/usr/libexec/getty Pc" xterm onifexists secure
Nach:
ttyv0 "/usr/libexec/getty al.user" xterm onifexists secure
Um noch X11 zu starten, kommt in die /home/user/.login:
if $tty == ttyv0 startx
EncFS
Bitte nicht verwenden!
Bisschen basteln musste ich schon, um EncFS zum laufen zu bekommen. Hier meine Beobachtungen.
Zuerst installieren:
pkg install fusefs-encfs
… oder aus den Ports bauen.
Dann kommt in die /etc/rc.conf:
fusefs_enable="YES"
Die /etc/devfs.rules wird wiefolgt erweitert (oder ggf. erstellt):
[system=10]
add path 'fuse*' mode 0666
Diese Regel in der /etc/rc.conf aktivieren:
devfs_system_ruleset="system"
Jetzt das Wichtigste: Der User, der EncFS nutzen möchte muss Teil der
Gruppe operator sein!
Bin ich vielleicht schon drin?
pw groupshow operator
Nein? Dann wird es aber Zeit!
pw groupmod operator -m user
Manchmal reicht das immer noch nicht, man muss den usermount noch
explizit erlauben.
Sieht man folgendes bei sysctl vfs.usermount:
vfs.usermount: 0
Dann kommt noch folgendes in die /etc/sysctl.conf:
vfs.usermount=1
Hardware Bell
Meine Finger sind wohl zu dick, ich vertippe mich auf der Console recht häufig.. Das vorwurfsvolle, sehr laute piepen geht mir auf den Zeiger.
Unter
vt
funktioniert ein beherztes kbdcontrol -b quiet.off.
D.h. in die /etc/rc.conf kommt ein:
allscreens_kbdflags="-b quiet.off"
Wenn das nicht funktioniert, hilft in der /etc/sysctl.conf folgendes:
kern.vt.enable_bell=0
Sollte man etwas von hw.syscons.bell=0 lesen, ist man womöglich
auf dem falschen Dampfer, dies bezieht sich nur auf
sc.
sc ist veraltet und wird i.d.R. nicht mehr genutzt.
SSH-Server im Live-System
Es ist möglich im Live-System einen SSH-Server zu starten. Man muss nur wissen, wie.
Zum Glück hab ich es hier mal aufgeschrieben!!1!
Das sind eigentlich nur drei Schritte.
- SSH-Server umkonfigurieren, um Logins für
rootzu erlauben. - Ein Passwort für
rootsetzen. - Server starten
Das Problem: Im Live-System kann man nicht nach /etc schreiben
(nur in die beiden Ramdisks unter /var und /tmp).
Aber da gibt’s doch was von UnionFS:
mkdir /tmp/etc
mount_unionfs /tmp/etc /etc
Fein! Ab jetzt werden alle Änderungen in /etc in die Ramdisk von /tmp
geschrieben.
In die /etc/ssh/sshd_config kommt:
PermitRootLogin yes
Dann ein Passwort setzen und SSH-Server starten:
passwd root
service sshd onestart
Da sich die Hostkeys im Installer beim Neustart ändern, empfehlen sich am Client zwei Optionen:
ssh \
-o StrictHostKeyChecking=no \
-o UserKnownHostsFile=/dev/null \
root@....
make.conf - Headless Server
Auf einem Server braucht man nicht zingend alle Abhänigkeiten, wenn man sich Software aus den Ports baut.
Zum Beispiel kann man X11 komplett ignorieren.
Hier meine /etc/make.conf wie ich sie einsetze:
# Build
MAKE_JOBS_NUMBER?=8
# Optimizations
CPUTYPE?=native
OPTIONS_SET=OPTIMIZED_CFLAGS CPUFLAGS
# Options
OPTIONS_SET+=ICONV
OPTIONS_UNSET=CUPS DEBUG DOCS EXAMPLES FONTCONFIG NLS TEST X11
WITHOUT_MODULES=sound ntfs
WITHOUT_X11=yes
DEFAULT_VERSIONS+=ssl=openssl
-
MAKE_JOBS_NUMBERsollte der Anzahl der CPU Kerne entsprechen. -
OPTIONS_UNSETwählt bei den Dialogen die entsprechenden Optionen ab. Am wichtigsten sind hierCUPS,FONTCONFIGundX11. Diese würden unendlich viele Abhänigkeiten mit rein ziehen, falls man diese anwählt.
mDNS mit Avahi
Damit die Kiste im lokalen Netz unter $(hostname).local auffindbar wird
braucht es avahi und einen mDNS-Responder:
pkg install avahi nss_mdns
Beide benötigen dbus, also schalten wir das in der /etc/rc.conf ein:
dbus_enable="YES"
avahi_daemon_enable="YES"
Dann noch in der /etc/nsswitch.conf die Zeile:
hosts: files dns
ändern zu:
hosts: files dns mdns
Newcons Console
Wird kein Grafiktreiber geladen, kommt die Text-Console mit einer Auflösung von 640x480 oder noch schlimmer daher..
Ist jedoch einer vorhanden, dann wird
vt (newcons) anstelle von
sc geladen, und man hat endlich
Übersicht auf der Console.
Je nach Grafikkarte kommt also eine der folgenden Zeilen in die
/boot/loader.conf:
i915kms_load="YES"
nvidia_load="YES"
radeonkms_load="YES"
vga_load="YES"
Will man den Start von vt erzwingen, so kommt noch folgendes hinzu
(eigentlich nur nötig sofern man noch kein
UEFI
nutzt):
kern.vty=vt
Mit dmesg | grep drm findet man die Interfaces und kann dann
die Auflösung z.B. noch so beeinflussen:
kern.vt.fb.default_mode="1280x800"
kern.vt.fb.LVDS-1="1024x768"
NTPd listen local
In der Standardkonfiguration lauscht der NTP Daemon auf allen Adressen.
Das ist nicht immer das was man haben möchte:
sockstat -l64 | grep :123
root ntpd 59359 20 udp6 *:123 *:*
root ntpd 59359 21 udp4 *:123 *:*
root ntpd 59359 22 udp4 11.22.33.44:123 *:*
root ntpd 59359 23 udp6 fe80::11:22:33:44%em0:123 *:*
root ntpd 59359 24 udp6 2001:11:22:33:44::1:123 *:*
root ntpd 59359 25 udp6 ::1:123 *:*
root ntpd 59359 26 udp6 fe80::1%lo0:123 *:*
root ntpd 59359 27 udp4 127.0.0.1:123 *:*
In der /etc/ntp.conf kann man das beheben:
interface ignore wildcard
Damit lauscht ntpd nur noch auf den Adressen von lo0.
Das Interface lässt sich dennoch sezten:
interface listen em0
Somit bindet sich ntpd nur noch auf die Adressen von em0.
Alternativ kann man Adressen auch direkt angeben:
interface listen IPv4 11.22.33.44
interface listen IPv6 2001:11:22:33:44::1
Wichtig ist hierbei die große schreibweise von IP. Wenn man das klein schreibt, dann wird das stillschweigend ignoriert..
Neu starten:
service ntpd restart
Läuft:
sockstat -l64 | grep :123
root ntpd 94185 20 udp4 11.22.33.44:123 *:*
root ntpd 94185 21 udp6 fe80::11:22:33:44%em0:123 *:*
root ntpd 59359 22 udp6 2001:11:22:33:44::1:123 *:*
root ntpd 59359 23 udp6 ::1:123 *:*
root ntpd 94185 24 udp4 127.0.0.1:123 *:*
Mit ntpq -pn und/oder ntpq -c as kann man noch ausführlicher
überprüfen, ob alles funktioniert.
Nutzer umbenennen
Wenn man SD-Karten Image von FreeBSD nutzt (z.B. auf dem Beaglebone) dann existieren dort bereits zwei Nutzer: root & freebsd
Im folgenden nenne ich den freebsd Nutzer um in user.
Am besten macht man dies ziemlich früh nach dem flashen und ersten starten des Systems.
Als root einloggen (und vorher alle anderen Nutzer ausloggen).
In vipw ändert man folgende Zeile von:
freebsd:$6$...:1001:1001::0:0:FreeBSD User:/home/freebsd:/bin/csh
nach:
user:$6$...:1001:1001::0:0:Some User:/home/user:/bin/csh
Dann noch das Home-Verzeichnis umbenennen:
mv /home/freebsd /home/user
Als letztes wird mit vigr noch die Gruppe umbenannt.
Dazu müssen zwei Zeilen geändert werden:
wheel:*:0:root,freebsd
…
freebsd:*:1001:
nach:
wheel:*:0:root,user
…
user:*:1001:
Nun sollte man sich als user am System einloggen können, und Mitglied in den Gruppen user sowie wheel sein.
Secure sSMTP
Bitte nicht verwenden!
In manchen Situationen will man sich nicht immer einen Sendmail ans Bein binden, lieber lässt man E-Mails über einen fremden SMTP Server laufen.
In diesem Artikel gehen wir von folgenden Parametern aus:
| Name | Wert |
|---|---|
| Hostname | kiste |
| Domain | sample.org |
| SMTP Server | mail.example.com |
| SMTP Port | 587 |
| Nutzername | user@example.com |
| Passwort | VerySecret1 |
Wir wollen Letztendlich die Mails an someone@whatever.com verschicken.
Sendmail deaktivieren
Dies macht man durch ein paar Einträge in der /etc/rc.conf:
sendmail_enable="NO"
sendmail_submit_enable="NO"
sendmail_outbound_enable="NO"
sendmail_msp_queue_enable="NO"
Danach versuchen jegliche Sendmail Instanz abzuschießen:
killall sendmail
sSMTP installieren
cd /usr/ports/mail/ssmtp
make config-recursive install replace clean
Die replace Anweisung ersetzt Sendmail als
Standard in /etc/mail/mailer.conf.
Nochmal nachschauen: Die Einträge mit /usr/libexec/sendmail/sendmail
sollten auskommentiert worden sein, und es sollten neue Einträge drin sein
mit /usr/local/sbin/ssmtp.
Weiterhin sollten der User und die Gruppe ssmtp erstellt worden sein.
sSMTP einrichten
Die Konfiguration wird unter /usr/local/etc/ssmtp gesucht.
Der Ordner sollte existieren und der Gruppe ssmtp gehören.
Die Einstellungen in der /usr/local/etc/ssmtp/ssmtp.conf:
Root=postmaster
MailHub=mail.example.com:587
#RewriteDomain=whatever.com
Hostname=kiste.sample.org
FromLineOverride=YES
UseSTARTTLS=YES
AuthUser=user@example.com
AuthPass=VerySecret1
Root: Der Empfänger an die die Mails für den root User gehen sollen. Es ließe sich auch direkt eine Mail-Adresse da rein schreiben, jedoch ist es die saubere Lösung dortpostmasterzu hinterlegen und dafür einen Alias zu setzen.MailHub: Der SMTP Server, an dem die Mails abgeliefert werdenRewriteDomain: Manchmal sinnvol zu setzen, wegen Spamfilter und/oder Rückantworten (falls gewünscht). Sollte dann aufwhatever.comgesetzt werden.Hostname: Der Hostname des Computers. Kann ein voller sein, oder bei aktiviertemRewriteDomainauch nur der kurze Hostname (kiste)FromLineOverride: Ermöglicht es dem Email Programm einFrom:zu setzen.UseSTARTTLS(oder ggf.UseTLS): Verschlüsselung zum SMTP Server.AuthUser: Der SMTP Username.AuthPass: Das SMTP Passwort (deshalb besonders auf die Dateirechte dieser Config achten).
Falls man dies nicht schon getan hat: In pf sollte auch der entsprechende
Port aufgemacht werden, damit die Mail auch raus kann.
587 == submission:
pass out proto tcp from any to any port = submission flags S/SA keep state
Sollte man den Port 465 nutzen wollen, muss man den Port
entsprechend anpassen, und UseSTARTTLS durch UseTLS
austauschen. Der Port heißt in pf dann smtps.
Funktionstest
Zum testen, ob das Mail versenden funktioniert kann man folgendes ausprobieren:
mail someone@whatever.com < cat /etc/motd
Oder direkt per Username:
mail root < cat /etc/motd
Aliase
Nachdem alles so grob funktionert, kann man sich Aliase setzen.
sSMTP verweigert den newaliases Befehl::
newaliases: Aliases are not used in sSMTP
Somit fällt auch die /etc/aliases hinten runter.
Aber man kann sich in der /etc/mail.rc für einzelne Benutzer trotzdem
noch aliase setzen::
alias postmaster 'Master Of Post'<someone+postmaster@whatever.com>
alias root 'Awesome Super User'<someone+root@whatever.com>
alias user 'Not So Awesome User'<someone+user@whatever.com>
Hier verwende ich Kommentare in den Adressen, damit ich meinen Mailfilter darauf ansetzen kann.
Absender Name
Die (Menschenlesbaren-) Namen des Absenders werden aus der /etc/passwd
gezogen. Falls man darin Sachen ändern möchte,
unbedingt vipw verwenden!!1!
System Locale
Bitte so nicht machen!
Die Umgebungsvariable LANG=xx_YY.ZZZZ beschreibt:
- die Sprache
xx - Länder Kennung
YY - Encoding
ZZZZ
locale zeigt die momentan aktive an, locale -a alle vorhandenen.
Um diese systemweit zu setzen, muss man an diese in an
default-Sektion in der /etc/login.conf anhängen:
default:\
...
:priority=0:\
:ignoretime@:\
:umask=022:\
:charset=UTF-8:\
:lang=en_US.UTF-8:\
:setenv=LC_COLLATE=C:
Danach die login Datenbank mit cap_mkdb /etc/login.conf neu bauen.
Non-Login-Shells bekommen die locale z.B. durch die
/etc/profile mitgeteilt:
LANG=en_US.UTF-8; export LANG
CHARSET=UTF-8; export CHARSET
Nach einem neuen Login, sollte locale nun
was anderes als LANG=C anzeigen.
Trackpoint Scrolling
Mein Thinkpad hat einen Trackpoint. Feine Sache das! Aber noch besser wäre es, die mittlere Taste auch zum scrollen zu verwenden.
Dazu muss man nicht im X-Server rumfrickeln, moused kümmert
sich drum.
In die /etc/rc.conf kommen also zwei Zeilen:
moused_enable="YES"
moused_flags="-VH"
Virt Host
Neuen Hobel auf der Server-Börse geschossen. Mehr Hardware, mehr schnell. Selber Preis. Why not?!?
Lass mal den Ezjail Host umziehen. Dabei Thick Jails fahren…
Altlasten und Dellen aus dem alten Setup fixen. Mehr dokumentieren.
So der Plan…
- Installation
- FreeBSD installieren
- Rescue system,
qemu,mfsbsd&chroot– Inception!
- Rescue system,
- FreeBSD installieren
- Einrichten
- Netzwerk glatt ziehen
- Tools einrichten
- Pools
- Partitionen verschlüsseln
- Remote unlock einrichten
- Jails
Installation
Vom Hoster gibt es keine FreeBSD Images mehr. Großer Schock!
Das Rescue System hat OpenZFS und qemu am Start. Dann aus dem alten Host und Zeug noch Wissen gezogen.
Der Plan: mfsbsd mittels qemu starten, die Festplatten
durchreichen und von Hand da FreeBSD rein installieren.
Hintergrund
Im Server sind 2x 10TB Festplatten verbaut. Will große Dateien hosten und Thick Jails laufen lassen. Deshalb keine SSDs. Habe einfach auch keine Lasten die schnellen Disk-IO benötigen.
Auch werde ich kein EFI aufsetzen. Sind mir zu viele bewegliche Teile die kaputt gehen können. Ob der Bootloader fancy aussieht ist im Rack egal (Jajaja, Kernelmodule, ich weiß…).
Die zwei Festplatten bekommen einen Mirror verpasst:
| Name | Size | Type | ||
|---|---|---|---|---|
boot0, boot1 | 512K | freebsd-boot | 2x einzeln | 🔓 |
swap0, swap1 | 16G | freebsd-swap | gmirror eli | 🔑 |
core0, core1 | 64G | freebsd-zfs | fürs system | 🔓 |
virt0, virt1 | 1024G | freebsd-zfs | für jails | 🔑 |
data0, data1 | rest | freebsd-zfs | für files | 🔑 |
Bootstrapping
- Server ins Rescue-System booten.
- Verbinden mit
ssh -o StrictHostKeyChecking=no… - Linux Kram:
apt updateapt install tmux htop curl
mfsbsd im App-Store laden:
curl -O https://mfsbsd.vx.sk/files/iso/14/amd64/mfsbsd-14.1-RELEASE-amd64.iso
Ab jetzt sollten wir in tmux sein…
qemu-system-x86_64 \
-net nic -net user,hostfwd=tcp::1022-:22 -m 2048M -enable-kvm \
-cpu host,+nx -M pc -smp 2 -vga std -k en-us \
-cdrom ./mfsbsd-14.1-RELEASE-amd64.iso \
-device virtio-scsi-pci,id=scsi0 \
-drive file=/dev/sda,if=none,format=raw,discard=unmap,aio=native,cache=none,id=n0 \
-device scsi-hd,drive=n0,bus=scsi0.0 \
-drive file=/dev/sdb,if=none,format=raw,discard=unmap,aio=native,cache=none,id=n1 \
-device scsi-hd,drive=n1,bus=scsi0.0 \
-boot once=d -monitor stdio
Neue console in tmux, und ssh -p 1022 root@localhost.
Passwort ist mfsroot.
Partitionieren
Die zwei Platten haben die Devices /dev/da0 & /dev/da1 bekommen.
Für das momentane System zfs laden und 4K Sektoren erzwingen:
kldload zfs
sysctl vfs.zfs.min_auto_ashift=12
Bootsektoren der Platten nullen:
dd count=2 if=/dev/zero of=/dev/da0
dd count=2 if=/dev/zero of=/dev/da1
Partitionstabelle anlegen:
gpart create -s GPT da0
gpart create -s GPT da1
Die Partitionen (nach Tabelle oben) erstellen:
gpart add -a 4k -t freebsd-boot -s 512K -l boot0 da0
gpart add -a 4k -t freebsd-boot -s 512K -l boot1 da1
gpart add -a 4k -t freebsd-swap -s 16G -l swap0 da0
gpart add -a 4k -t freebsd-swap -s 16G -l swap1 da1
gpart add -a 4k -t freebsd-zfs -s 64G -l core0 da0
gpart add -a 4k -t freebsd-zfs -s 64G -l core1 da1
gpart add -a 4k -t freebsd-zfs -s 1024G -l virt0 da0
gpart add -a 4k -t freebsd-zfs -s 1024G -l virt1 da1
gpart add -a 4k -t freebsd-zfs -l data0 da0
gpart add -a 4k -t freebsd-zfs -l data1 da1
Unter /dev/gpt sollten alle Partitionen als Devices vorhanden sein.
Boot Partition
Partitionen markieren:
gpart set -a bootme -i 1 da0
gpart set -a bootme -i 1 da1
Bootloader kommt beim chroot ins installierte System. Stay tuned.
Swap
Es reicht hier den Mirror zu erstellen.
gmirror label swap gpt/swap0 gpt/swap1
In das Ziel-System kommt später noch ein Eintrag in die fstab.
Pools & Datasets
Das Installations-Target ist /mnt.
Für das System selbst – core:
zpool create \
-f -m none \
-o cachefile=/boot/zfs/zpool.cache \
-o altroot=/mnt \
-O compression=lz4 \
-O atime=off \
core mirror gpt/core0 gpt/core1
zfs create -o mountpoint=none core/ROOT
zfs create -o mountpoint=/ core/ROOT/default
zfs create -o mountpoint=/usr -o canmount=off core/usr
zfs create -o setuid=off core/usr/ports
zfs create core/usr/home
zfs create core/usr/local
zfs create core/usr/obj
zfs create core/usr/src
zfs create -o mountpoint=/var -o canmount=off core/var
zfs create -o atime=on core/var/mail
zfs create -o setuid=off -o exec=off core/var/audit
zfs create -o setuid=off -o exec=off core/var/crash
zfs create -o setuid=off -o exec=off core/var/log
zfs create -o setuid=off core/var/tmp
zfs create core/var/db
Boot Environment setzen:
zpool set bootfs=core/ROOT/default core
Die Partitionen virt und data werden verschlüsselt.
Deshalb bleiben diese erstmal liegen – wird gemacht wenn das System läuft.
System Installieren
Wir brauchen die zwei Disketten in Laufwerk A: & B::
fetch https://download.freebsd.org/releases/amd64/14.2-RELEASE/base.txz
fetch https://download.freebsd.org/releases/amd64/14.2-RELEASE/kernel.txz
# check
fetch https://download.freebsd.org/releases/amd64/14.2-RELEASE/MANIFEST
grep "$(sha256 -q base.txz)" MANIFEST
grep "$(sha256 -q kernel.txz)" MANIFEST
Auspacken:
tar -C /mnt -xf base.txz
tar -C /mnt -xf kernel.txz
Das wars. Feierabend!
Konfigurieren
Die boot/loader.conf:
cat << LOL >> /mnt/boot/loader.conf
cryptodev_load="YES"
geom_eli_load="YES"
geom_mirror_load="YES"
zfs_load="YES"
vfs.root.mountfrom="zfs:core/ROOT/default"
kern.geom.label.disk_ident.enable="0"
kern.geom.label.gptid.enable="0"
security.bsd.allow_destructive_dtrace="0"
fdescfs_load="YES"
nullfs_load="YES"
tmpfs_load="YES"
LOL
Eine fstab im Zielsystem erzeugen:
cat << LOL >> /mnt/etc/fstab
tmpfs tmp tmpfs rw,mode=1777 0 0
/dev/mirror/swap.eli none swap sw 0 0
LOL
Berechtigungnen für /tmp setzen:
chmod 1777 /mnt/tmp
chmod 1777 /mnt/var/tmp
Die Zeitzone verlinken (Ziel existiert noch nicht, bzw. unter altroot /mnt):
ln -s /usr/share/zoneinfo/Europe/Berlin /mnt/etc/localtime
Home-Folder verlinken (Ziel existiert hier auch noch nicht wegen altroot):
ln -s /usr/home /mnt/home
Und die rc.conf:
cat << LOL >> /mnt/etc/rc.conf
# Filesystem
zfs_enable="YES"
dumpdev="AUTO"
# Network
hostname="machine"
ifconfig_em0="DHCP"
ifconfig_em0_ipv6="inet6 accept_rtadv"
resolv_enable="NO"
# Daemons
syslogd_flags="-ss"
powerd_enable="YES"
sshd_enable="YES"
ntpd_enable="YES"
ntpd_sync_on_start="YES"
sendmail_enable="NO"
sendmail_submit_enable="NO"
sendmail_outbound_enable="NO"
sendmail_msp_queue_enable="NO"
LOL
Anmerkung der Redaktion: Der Name vom Interface kann anders sein.
Für mich ist es igb0.
Es lohnt sich auch mal Notizen zu machen was für eine Netzwerk-Config das
Rescue-System per DHCP bekommen hat (z.B. Gateway-Adresse).
Kernel Zeug:
cat << LOL >> /mnt/etc/sysctl.conf
# force 4K sectors
vfs.zfs.min_auto_ashift=12
# hardening
security.bsd.unprivileged_read_msgbuf=0
security.bsd.unprivileged_proc_debug=0
kern.randompid=1
LOL
DNS wäre auch ganz nett:
cat << LOL >> /mnt/etc/resolv.conf
nameserver 2620:fe::fe
nameserver 2620:fe::9
nameserver 149.112.112.112
nameserver 9.9.9.9
LOL
Changeroot
Vorbereiten:
mount -t devfs devfs /mnt/dev
mount -t tmpfs tmpfs /mnt/tmp
Wir können das System erstmalig nutzen:
chroot /mnt
-
Symlinks checken:
- Passt
/homenach/usr/home? - Zeigt
/etc/localtimenicht ins leere?
- Passt
-
Root Passwort mit
passwdsetzen. -
User mit
addusererstellen (in Gruppewheeleinladen). -
pkgzum Leben erwecken…-
pkg info -ao -
pkg install sudo-
In der
/usr/local/etc/suodersdiese Zeile auskommentieren:%wheel ALL=(ALL:ALL) ALL
-
-
Hier wäre die Stelle wo sich weitere Sachen installieren lassen, oder zumindest Updates machen…
- Je nachdem was man haben möchte.
-
-
sshKeys hinterlegen:mkdir ~user/.ssh- Key in
~user/.ssh/authorized_keyshinterlegen.- Auf dem Web-Host hinterlegen und dann mit
fetch. - Das Clipboard funktioniert zufällig?
- Irgendwas mit
scp… - Morse-Telegraphie…
- Auf dem Web-Host hinterlegen und dann mit
chown -R user:user ~user/.sshchmod 700 ~user/.ssh
-
Wichtig! Bootloader installieren:
gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 da0 gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 da1 -
Fertig:
exit!
Anmerkung der Redaktion: Beim letztendlichen installieren des Servers war
der Order /var/home/user leer, was den Login mit ssh Keys bisschen
schwierig macht.
Irgendwas mache ich falsch hier. Der Workaround:
/var/home/userin ein/usr.tgzfile legencp /var/home/user/.ssh/authorized_keys /root/.ssh/authorized_keysPermitRootLogin prohibit-passwordfürsshdsetzen- Nach dem ersten Start
/usr.tgzentpacken undPermitRootLogin nosetzen.
Pools exportieren
-
ZFS-Cache-File rüber kopieren:
cp /boot/zfs/zpool.cache /mnt/boot/zfs/zpool.cache -
Die chroot Filesysteme aushängen und die Pools exportieren:
umount /mnt/devumount /mnt/tmpzpool export coremountsollte wieder so gut wie leer sein…
Fertig
Jetzt aber wirklich Feierabend!
Das mfsbsd mit einem shutdown -p now sauber runterfahren.
qemu beendet sich.
Dem Rescue-System noch einen guten Tag wünschen, und reboot.
Danach Einrichten.
Einrichten
Frisch installiert kommt der Server zum Ersten mal hoch.
ssh login funktioniert, sudo auch? Sehr gut.
Netzwerk
Als erstes kümmert man sich um korrektes Netzwerk. Die /etc/rc.conf
wird von DHCP auf fixe Adressen umgestellt:
# Network
hostname="machine"
ifconfig_igb0="inet <v4 Adresse vom Server>/32"
gateway_if="igb0"
gateway_ip="<v4 Adresse vom Gateway>"
static_routes="gateway default"
route_gateway="-host $gateway_ip -interface $gateway_if"
route_default="default $gateway_ip"
ipv6_default_interface="igb0"
ifconfig_igb0_ipv6="inet6 <v6 Adresse vom Server> prefixlen 64 accept_rtadv"
ipv6_defaultrouter="fe80::1%igb0"
resolv_enable="NO"
Anmerkung der Redaktion: Kommt auf den Treiber an wie der Device-Name
ist: em0, bge0, … – Oder wie bei mir: igb0.
Das Netzwerk-Setup wird später noch für die Jails angepasst.
Plan: Die Jails kommunizieren über eine Bridge, der Traffic mittels pf
geregelt.
Obacht - beim intitalen Aufsetzen einer Bridge hatte ich dazu noch
ipv6_gateway_enable & gateway_enable an. Folge: Die MAC-Adresse der
Bridge wurde von igb0 rausgegeben, gab böse Mails vom Hoster.
OpenSSH abdichten
Orientiere mich dabei an der cipherlist will aber (da es beim
OS-Update nervt) die /etc/ssh/sshd_config nicht anfassen.
Deshalb kommt in die /etc/rc.config mittlerweile so was:
# OpenSSH
sshd_flags=" \
-o ListenAddress=<v4 Adresse vom Server>:23 \
-o ListenAddress=[<v6 Adresse vom Server>]:23 \
-o Protocol=2 \
-o HostKey=/etc/ssh/ssh_host_ed25519_key \
-o HostKey=/etc/ssh/ssh_host_rsa_key \
-o HostKeyAlgorithms=ssh-ed25519,rsa-sha2-512,rsa-sha2-256 \
-o KexAlgorithms=curve25519-sha256@libssh.org,curve25519-sha256,diffie-hellman-group18-sha512,diffie-hellman-group16-sha512,diffie-hellman-group14-sha256,diffie-hellman-group-exchange-sha256 \
-o Ciphers=chacha20-poly1305@openssh.com,aes256-gcm@openssh.com,aes128-gcm@openssh.com,aes256-ctr,aes192-ctr,aes128-ctr \
-o MACs=hmac-sha2-512-etm@openssh.com,hmac-sha2-256-etm@openssh.com,umac-128-etm@openssh.com \
-o PermitRootLogin=no \
-o IgnoreRhosts=yes \
-o PasswordAuthentication=no \
-o PermitEmptyPasswords=no \
-o KbdInteractiveAuthentication=no \
-o UsePAM=no \
-o X11Forwarding=no \
"
sshd_enable="YES"
Erwischt: Ja ich nutze den telnet Port für ssh.
NTPd listen local
Da habe ich noch keine Lösung wie man das mit ntpd_flags hin bekommt.
sockstat -l verrät uns, dass der NTPd auf jedem Interface Port 123
lauscht.
Die /etc/ntp.conf bekommt ein interface ignore wildcard,
so wie auf einer eigenen Seite beschrieben.
Firewall
Noch nichts spannendes damit geplant, aber wenn Jails dazu kommen ist es gut
eine Grundlage zu haben - /etc/pf.conf:
# public addresses
ip_igb0_p4 = "<v4 Adresse vom Server>"
ip_igb0_p6 = "<v6 Adresse vom Server>"
# tables
table <tbl_allow> const { "my.other.host.example.net", "dyndns.example.org" }
table <tbl_block> persist {}
# services hosted on this box
# 60000: mosh
inbound_tcp = "{ telnet }"
inbound_udp = "{ 60000:60010 }"
# services consumed by this box
outbound_tcp = "{ ssh, telnet, domain, http, https, ftp }"
outbound_udp = "{ domain, ntp }"
# icmp types
icmp_types_p4 = "{ echoreq, unreach }"
icmp_types_p6 = "{ echoreq, echorep, unreach, toobig, timex, routersol, routeradv, neighbrsol, neighbradv, redir }"
# allow loopback traffic
set skip on { lo0 }
# do not reject, just drop
set block-policy drop
# incoming traffic is normalized and defragmented
scrub in on igb0 all fragment reassemble
# default rule - block all
block log all
# apply tables
block drop in from <tbl_block> to any
pass in from <tbl_allow> to any
# allow ping
pass inet proto icmp all icmp-type $icmp_types_p4 keep state
pass inet6 proto icmp6 all icmp6-type $icmp_types_p6 keep state
# allow access to outside world
pass out proto tcp to any port $outbound_tcp keep state
pass out proto udp to any port $outbound_udp keep state
# allow outside access into this box
pass in log proto tcp to any port $inbound_tcp keep state (max-src-conn 5, max-src-conn-rate 2/10, overload <tbl_block> flush global)
pass in log proto udp to any port $inbound_udp keep state (max-src-conn 5, max-src-conn-rate 2/10, overload <tbl_block> flush global)
- Eher unspannend, von außen sind nur noch die Ports
telnet(fürssh) und die60000er Range fürmoshoffen. - Wichtiger sind die zwei Tables:
- tbl_allow
- Sind fixe Adressen von meinen anderen Kisten.
- Soll verhindern, dass ich mich versehentlich aussperre.
- tbl_block
- Wird auf alle offenen Ports angesetzt und macht ein Rate-Limiting
- Wehrt stumpfsinnige DoS Angriffe ab.
- Das
pf_authScript erweitert die noch um Einträge aus der/var/log/auth.log.
- tbl_allow
In der /etc/rc.conf noch einschalten:
# Firewall
pf_enable="YES"
pf_rules="/etc/pf.conf"
pflog_enable="YES"
pflog_logfile="/var/log/pflog"
(Wobei man pflog auch weglassen kann.)
Tools
Habe mir im Laufe der Zeit eine paar Scripte geschrieben die das Leben einfacher machen.
pkg install vim git-lite
(git-lite bringt weniger Abhängigkeiten mit als git, gut für den Server)
Und dann als User klonen:
mkdir ~/code
cd ~/code
git clone https://github.com/spookey/dirty_little_helpers.git
git clone https://github.com/spookey/geli_remote_unlock.git
git clone https://github.com/spookey/say_cheese_zfs.git
git clone https://gitlab.com/spookey/quicksnap.git
quicksnap
Einfach, aber effektiv. Hat eine input.txt mit einem Pfad pro Zeile
und kopiert die Files rüber. Das ganze in ein git repo packen und zack, hat
man seine Config versioniert und ein Backup davon.
Erst mal einen Key anlegen:
ssh-keygen -t ed25519 -f `/root/.ssh/quicksnap_ed25519` -C 'root@machine'
Bei dem git Hoster des geringsten Misstrauens ein private Repo anlegen, und
/root/.ssh/quicksnap_ed25519.pub hinterlegen.
Eine entsprechende ssh config für root:
cat << LOL >> /root/.ssh/config
Host git.example.net
User git
IdentityFile ~/.ssh/quicksnap_ed25519
Host *
VisualHostKey true
LOL
Das Repo clonen:
mkdir /root/code
cd /root/code
git clone ssh://git.example.net/user/conf_machine.git
Als letztes noch das Wrapper-Script unter /root/bin/quicksnap
#!/usr/bin/env sh
INPUT=/root/code/conf_machine/input.txt \
OUTPUT=/root/code/conf_machine/output \
/usr/home/user/code/quicksnap/quicksnap.sh "$@"
dirty little helpers
Hier brauchen wir ein paar Sachen…
pf_auth
Macht nur Sinn, wenn man pf so eingerichtet hat, dass Einträge von
tbl_block auch wirklich blockiert werden.
Alles was wir brauchen ist ein Eintrag in der crontab von root:
*/2 * * * * /usr/home/user/code/dirty_little_helpers/pf_auth/pf_auth.sh -n 3 /var/log/auth.log >> /var/log/pf_auth.log 2>&1
Es lassen sich der auth.log Parameter mehrfach angeben.
Ab dem Moment wenn jails laufen sollte man den Eintrag noch
um /usr/jail/*/var/log/auth.log erweitern, um alles einzusammeln.
Log Rotation – /usr/local/etc/newsyslog.conf.d/pf_auth.conf:
cat << LOL >> /usr/local/etc/newsyslog.conf.d/pf_auth.conf
/var/log/pf_auth.log 644 4 * @T00 BCNX
LOL
jail_pkg_list
Die Paket-Namen mit Version einfach in einer Text-Datei speichern.
Das ganze ins quicksnap Repo legen, dann weiß man wann was installiert wurde.
ln -s /usr/home/user/code/dirty_little_helpers/jail_pkg_list/jail_pkg_list.sh /root/bin/jail_pkg_list
Und das ganze auch noch automatisch in der crontab von root:
*/30 * * * * /usr/home/user/code/dirty_little_helpers/jail_pkg_list/jail_pkg_list.sh > /var/log/jail_pkg_list.log
Geht auch als normaler user, aber aufpassen bei den Berechtigungen vom
Log-File.
jail_pkg
Einmal pkg für alle Jails ausführen.
Anwendungsfall zu 99% ist jail_pkg update und jail_pkg upgrade.
Hier reicht eine Verlinkung nach /root/bin (analog zu oben).
bootstrap_jail
Zum gleichförmigen erstellen der Jails gibt es diese Scripte.
Vorerst reicht nur eine Verlinkung von bjail_datasets & bjail_install
nach /root/bin.
say cheese
Macht automatisch zfs Snapshots, und räumt auch wieder auf.
Python ist durch vim schon längst da, aber es fehlt noch das Meta-Package:
pkg install python3
In der crontab von root noch einrichten:
# say cheese
1 * * * * /usr/local/bin/python3 /usr/home/user/code/say_cheese_zfs/take_snapshots.py auto_hourly >> /var/log/say_cheese.log 2>&1
11 * * * * /usr/local/bin/python3 /usr/home/user/code/say_cheese_zfs/purge_snapshots.py 24 H -p auto_hourly >> /var/log/say_cheese.log 2>&1
3 0 * * * /usr/local/bin/python3 /usr/home/user/code/say_cheese_zfs/take_snapshots.py auto_daily >> /var/log/say_cheese.log 2>&1
13 0 * * * /usr/local/bin/python3 /usr/home/user/code/say_cheese_zfs/purge_snapshots.py 7 d -p auto_daily >> /var/log/say_cheese.log 2>&1
5 0 * * 0 /usr/local/bin/python3 /usr/home/user/code/say_cheese_zfs/take_snapshots.py auto_weekly >> /var/log/say_cheese.log 2>&1
15 0 * * 0 /usr/local/bin/python3 /usr/home/user/code/say_cheese_zfs/purge_snapshots.py 4 w -p auto_weekly >> /var/log/say_cheese.log 2>&1
7 0 1 * * /usr/local/bin/python3 /usr/home/user/code/say_cheese_zfs/take_snapshots.py auto_monthly >> /var/log/say_cheese.log 2>&1
17 0 1 * * /usr/local/bin/python3 /usr/home/user/code/say_cheese_zfs/purge_snapshots.py 12 m -p auto_monthly >> /var/log/say_cheese.log 2>&1
9 0 1 1 * /usr/local/bin/python3 /usr/home/user/code/say_cheese_zfs/take_snapshots.py auto_yearly >> /var/log/say_cheese.log 2>&1
19 0 1 1 * /usr/local/bin/python3 /usr/home/user/code/say_cheese_zfs/purge_snapshots.py 2 y -p auto_yearly >> /var/log/say_cheese.log 2>&1
Nach und nach sollten die Snapshots jetzt eintrudeln.
Log Rotation – /usr/local/etc/newsyslog.conf.d/say_cheese.conf:
cat << LOL >> /usr/local/etc/newsyslog.conf.d/say_cheese.conf
/var/log/say_cheese.log 644 9 1000 * BCNX
LOL
geli remote unlock (rc Script)
Das rc Script kopieren:
cp /usr/home/user/code/geli_remote_unlock/geliremoteunlock /usr/local/etc/rc.d/
chown root:wheel /usr/local/etc/rc.d/geliremoteunlock
chmod +x /usr/local/etc/rc.d/geliremoteunlock
Erlaubt uns die Pools automatisch zu entsperren…
Pools
Von der Installation sind noch die leeren
Partitionen virt & data übrig.
Verschlüsseln
Keys erzeugen:
mkdir /root/keys
chmod 700 /root/keys
dd count=1 bs=256k if=/dev/random of=/root/keys/virt.key
dd count=1 bs=256k if=/dev/random of=/root/keys/data.key
Passphrases ohne Newlines in Files schreiben:
printf '…' > /root/keys/virt.pass
printf '…' > /root/keys/data.pass
chmod 600 /root/keys/*
Partitionen verschlüsseln:
geli init -s 4096 -l 256 -J /root/keys/virt.pass -K /root/keys/virt.key gpt/virt0
geli init -s 4096 -l 256 -J /root/keys/virt.pass -K /root/keys/virt.key gpt/virt1
geli init -s 4096 -l 256 -J /root/keys/data.pass -K /root/keys/data.key gpt/data0
geli init -s 4096 -l 256 -J /root/keys/data.pass -K /root/keys/data.key gpt/data1
Alles ist hoffentlich gut notiert.
Entsperren
Key plus Passphrase ist gleich entschlüsselte Partition:
geli attach -j /root/keys/virt.pass -k /root/keys/virt.key gpt/virt0
geli attach -j /root/keys/virt.pass -k /root/keys/virt.key gpt/virt1
geli attach -j /root/keys/data.pass -k /root/keys/data.key gpt/data0
geli attach -j /root/keys/data.pass -k /root/keys/data.key gpt/data1
Unter /dev/gpt sollten jetzt die *.eli Devices auftauchen.
Pools & Datasets
Jetzt darauf die Pools erstellen:
zpool create \
-f -m none \
-O compression=lz4 \
-O atime=off \
virt mirror gpt/virt0.eli gpt/virt1.eli
zfs create -o mountpoint=none virt/ROOT
zfs create -o mountpoint=/usr/jail virt/jail
zfs create virt/jail/demo
zfs create -o canmount=off virt/jail/demo/usr
zfs create -o setuid=off virt/jail/demo/usr/ports
zfs create virt/jail/demo/usr/home
zfs create virt/jail/demo/usr/local
zfs create virt/jail/demo/usr/obj
zfs create virt/jail/demo/usr/src
zfs create -o canmount=off virt/jail/demo/var
zfs create -o atime=on virt/jail/demo/var/mail
zfs create -o setuid=off -o exec=off virt/jail/demo/var/audit
zfs create -o setuid=off -o exec=off virt/jail/demo/var/crash
zfs create -o setuid=off -o exec=off virt/jail/demo/var/log
zfs create -o setuid=off virt/jail/demo/var/tmp
zfs create virt/jail/demo/var/db
zpool create \
-f -m none \
-O compression=lz4 \
-O atime=off \
data mirror gpt/data0.eli gpt/data1.eli
zfs create -o mountpoint=none data/ROOT
zfs create -o mountpoint=/var/data data/ROOT/default
zfs create -o mountpoint=/var/data/share data/share
zfs create -o atime=on data/share/cert
zfs create data/share/cert/dhparam
zfs create data/share/cert/dkim
zfs create data/share/cert/letsencrypt
zfs create -o setuid=off data/share/static
zfs create -o mountpoint=/var/data/store data/store
zfs create -o atime=on data/store/sync
zfs create data/store/media
Remote unlock
Wir haben das System soweit, Platten sind verschlüsselt.
Jedoch muss man nach jedem reboot wieder die Partitionen von Hand
mit geli attach entsperren.
Auch schlimm: Der Ordner /root/keys liegt im unverschlüsselten Bereich!
Später nicht einfach dort liegen lassen - sonst ist die ganze Plattenverschlüsselung umsonst, wenn einem der Server aus dem Rack geschraubt wird.
Ein offsite Backup machen (USB-Stick im Tresor oder so), und danach
/root/keys löschen.
geli remote unlock
Hab mir geli remote unlock gedängelt. Die Keys, und
Passphrases dazu werden verschlüsselt von einem anderen Host via ssh geholt.
Keys & Passphrases verschlüsseln:
openssl enc -aes-256-cbc -a -pbkdf2 -salt \
-in /root/keys/virt.key \
-out /root/keys/machine.virt.key.aes \
--pass "pass:…"
openssl enc -aes-256-cbc -a -pbkdf2 -salt \
-in /root/keys/virt.pass \
-out /root/keys/machine.virt.pass.aes \
--pass "pass:…"
openssl enc -aes-256-cbc -a -pbkdf2 -salt \
-in /root/keys/data.key \
-out /root/keys/machine.data.key.aes \
--pass "pass:…"
openssl enc -aes-256-cbc -a -pbkdf2 -salt \
-in /root/keys/data.pass \
-out /root/keys/machine.data.pass.aes \
--pass "pass:…"
Die pass:… Strings sind bitte andere Passwörter als für die .eli
Partitionen. Brauchen wir im rc Script.
Die *.aes files werden an der Gegenstelle hinterlegt…
Wie wo und wann genau im Repo nachlesen.
Die /etc/rc.conf wird bisschen umfangreich:
# geliremoteunlock
geliremoteunlock_enable="YES"
geliremoteunlock_pools="data virt"
geliremoteunlock_data_devices="gpt/data0 gpt/data1"
geliremoteunlock_virt_devices="gpt/virt0 gpt/virt1"
geliremoteunlock_keyfile_host="user@example.org"
geliremoteunlock_keyfile_ident="/root/.ssh/machine_unlock_ed25519"
geliremoteunlock_data_keyfile_name="machine.data.key.aes"
geliremoteunlock_data_keyfile_password="…"
geliremoteunlock_virt_keyfile_name="machine.virt.key.aes"
geliremoteunlock_virt_keyfile_password="…"
geliremoteunlock_passphrase_host="user@example.org"
geliremoteunlock_passphrase_ident="/root/.ssh/machine_unlock_ed25519"
geliremoteunlock_data_passphrase_name="machine.data.pass.aes"
geliremoteunlock_data_passphrase_password="…"
geliremoteunlock_virt_passphrase_name="machine.virt.pass.aes"
geliremoteunlock_virt_passphrase_password="…"
Von der Setup Seite das rc Script für geliremoteunlock
nicht vergessen…
Jails
Von der Pools Seite gibt es das virt/jail/demo Dataset.
Erstmal Platz machen:
zfs destroy -r virt/jail/demo
Installation
Um das nicht jedes mal von Hand zu machen gibt es die bootstrap_jail
Scripte von der Setup Seite.
Die Datasets (-c) werden so angelegt:
bjail_dataset -c virt/jail demo
Das andere Script kann installieren:
bjail_install \
-z /usr/share/zone/Europe/Berlin \
-d /etc/resolv.conf \
-x \
-r \
-p \
-m \
-t \
/usr/jail/demo
Parameter
-
-x-
Installation durchführen (Script nimmt sonst fertige Installation an)
Lädt
$(uname -r | ✨)/base.txznach/var/tmp, checkt SHA & Ausweispapiere. Erst dann wird die Jail enpackt.
-
-
-z-
Setzt einen symlink auf
/etc/localtimeinnerhalb der JailDa Host & Jail gleich sind, passen “zufällig” die Pfade.
-
-
-d-
Kopiert eine
/etc/resolv.confin die JailHier die vom Host, aber je nach Setup bietet sich hier ein Template an
-
-
-r-
/etc/rc.confin der Jail vorbereitenclear_tmp_enable="YES" syslogd_flags="-ss" cron_flags="-J 60" sendmail_enable="NO" sendmail_submit_enable="NO" sendmail_outbound_enable="NO" sendmail_msp_queue_enable="NO"
-
-
-p-
/etc/periodic.confin der Jail vorbereitendaily_output="/var/log/daily.log" daily_show_badconfig="YES" daily_status_security_output="/var/log/daily.log" weekly_output="/var/log/weekly.log" weekly_show_badconfig="YES" weekly_status_security_output="/var/log/weekly.log" monthly_output="/var/log/monthly.log" monthly_show_badconfig="YES" monthly_status_security_output="/var/log/monthly.log" security_show_badconfig="YES"
-
-
-m-
/etc/motd.templatefür die Jail schreiben+===========+ | demo jail | +===========+
-
-
-t-
/etc/fstab.demofür den Host erzeugentmpfs /usr/jail/demo/tmp tmpfs rw,mode=1777 0 0 /usr/src /usr/jail/demo/usr/src nullfs ro 0 0Für
/tmpeintmpfsund der Source Tree wird vom Host in den Container gemounted.
-
Netzwerk
Beim Setup wurde zunächst nur eine Verbindung zur Installation sicher gestellt. Für die Jails kommt eine Bridge zum Zuge, darauf lauschen dann die Jails.
Bridge
Die /etc/rc.conf erweitern:
gateway_enable="NO"
ipv6_gateway_enable="NO"
cloned_interfaces="bridge0"
ifconfig_bridge0="inet <private v4 Adresse der Bridge>/32"
ifconfig_bridge0_ipv6="inet6 <private v6 Adresse der Bridge> prefixlen 128"
jail_enable="YES"
jail_reverse_stop="YES"
Wichtig - Bei diesem Setup muss gateway_enable & ipv6_gateway_enable
inaktiv sein, sonst wird die (virtuelle) MAC-Adresse durch das normale
Netzwerk-Interface durchgereicht. Der Hoster mag sowas nicht und schickt
dann böse Mails 🙈.
Zu einem herkömmlichen Setup mit geklontem lo1 Interface gibt es
noch wenig Unterschied. Jetzt allerdings schon eine Bridge zu nutzen
lässt aber die Möglichkeit offen einige Jails mit VNET laufen zu lassen.
Firewall
Die /etc.pf.conf anpassen:
# public addresses
ip_igb0_p4 = "<v4 Adresse vom Server>"
ip_igb0_p6 = "<v6 Adresse vom Server>"
# jail addresses
ip_j_demo_p4 = "<v4 Adresse der Jail>"
ip_j_demo_p6 = "<v6 Adresse der Jail>"
# tables
table <tbl_allow> const { "my.other.host.example.net", "dyndns.example.org" }
table <tbl_block> persist {}
# services hosted on this box
# 60000: mosh
inbound_tcp = "{ telnet }"
inbound_udp = "{ 60000:60010 }"
# services consumed by this box
outbound_tcp = "{ ssh, telnet, domain, http, https, ftp }"
outbound_udp = "{ domain, ntp }"
# services hosted inside jails
inbound_tcp_j_demo = "{ http, https }"
inbound_udp_j_demo = "{}"
# icmp types
icmp_types_p4 = "{ echoreq, unreach }"
icmp_types_p6 = "{ echoreq, echorep, unreach, toobig, timex, routersol, routeradv, neighbrsol, neighbradv, redir }"
# allow loopback traffic
set skip on { lo0, bridge0 }
# do not reject, just drop
set block-policy drop
# incoming traffic is normalized and defragmented
scrub in on igb0 all fragment reassemble
# outbound traffic from jails
nat pass on igb0 inet from (bridge0:network) to any -> $ip_igb0_p4
nat pass on igb0 inet6 from (bridge0:network) to any -> $ip_igb0_p6
# redirect traffic into jails
rdr pass log on igb0 inet proto tcp from any to (igb0:network) port $inbound_tcp_j_demo -> $ip_j_demo_p4
#rdr pass log on igb0 inet proto udp from any to (igb0:network) port $inbound_udp_j_demo -> $ip_j_demo_p4
rdr pass log on igb0 inet6 proto tcp from any to (igb0:network) port $inbound_tcp_j_demo -> $ip_j_demo_p6
#rdr pass log on igb0 inet6 proto udp from any to (igb0:network) port $inbound_udp_j_demo -> $ip_j_demo_p6
# default rule - block all
block log all
# apply tables
block drop in from <tbl_block> to any
pass in from <tbl_allow> to any
# allow ping
pass inet proto icmp all icmp-type $icmp_types_p4 keep state
pass inet6 proto icmp6 all icmp6-type $icmp_types_p6 keep state
# allow access to outside world
pass out proto tcp to any port $outbound_tcp keep state
pass out proto udp to any port $outbound_udp keep state
# allow outside access into this box
pass in log proto tcp to any port $inbound_tcp keep state (max-src-conn 5, max-src-conn-rate 2/10, overload <tbl_block> flush global)
pass in log proto udp to any port $inbound_udp keep state (max-src-conn 5, max-src-conn-rate 2/10, overload <tbl_block> flush global)
Somit wird jeder Traffic auf Port 80 & 443 in die Demo-Jail gesteckt, raus
kommt diese fein über ein NAT…
Jail Config
Jetzt noch schnell die losen Enden zusammen binden.
Die /etc/jail.conf erstellen:
path = "/usr/jail/${name}";
mount.fstab = "/etc/fstab.${name}";
mount.devfs;
host.hostname = "${name}";
exec.clean;
exec.consolelog = "/var/log/jail_console_${name}.log";
exec.system_user = "root";
exec.jail_user = "root";
exec.start = "";
exec.start += "/bin/sh /etc/rc";
exec.stop += "/bin/sh /etc/rc.shutdown jail";
demo {
ip4.addr = "bridge0|<v4 Adresse der Jail>";
ip6.addr = "bridge0|<v6 Adresse der Jail>";
}
Das müsste alles gewesen sein. Mit einem service jail start demo sollte
diese starten. Ein Login in die Jail geht so: jexec demo login -f root.
venv
Die Paketliste am System muss klein bleiben.
Python Pakete werden also immer in ein venvinstalliert.
Daraus den Interpreter nutzen, dann sind die Abhängigkeiten dabei.
Build Script
Das Script /usr/venv/build.sh gebastelt:
#!/usr/bin/env sh
NAME="$1"; shift
[ -z "$NAME" ] && {
echo "name required"
exit 1
}
python3 -m venv /usr/venv/$NAME || exit 1
/usr/venv/$NAME/bin/pip3 install -U pip || exit 1
[ -n "$*" ] && {
/usr/venv/$NAME/bin/pip3 install "$@" || exit 1
}
exit 0
Setup
Installieren wird zum Kinderspiel – z.B. tarsnapper ist so ein Kandidat
(Artikel alter Host).
Dafür reicht:
/usr/venv/build.sh tarsnapper tarsnapper
Updates werden so eine Sache, man muss sich an die Dependencies erinnern…
Deshalb:
printf 'tarsnapper\n' > /usr/venv/requirements-tarsnapper.txt
/usr/venv/build.sh tarsnapper -r /usr/venv/requirements-tarsnapper.txt
Das Kommando liegt im bin Order vom venv:
/usr/venv/tarsnapper/bin/tarsnapper --help
Source
Damit etcupdate (und mergemaster) funktioniert braucht es /usr/src.
Direkt aus der Quelle:
git clone https://git.FreeBSD.org/src.git /usr/src
Auf Stand bringen (zum Zeitpunkt des entstehens war das 14.2.0-p1):
git -C /usr/src checkout release/14.2.0-p1
Ansonsten
Zeug wegräumen:
git -C /usr/src reset --hard
Updates ziehen:
git -C /usr/src fetch --prune --prune-tags --tags --all
git -C /usr/src pull
Und dann:
git -C /usr/src checkout release/<sowieso>
Jails
Will Thick-Jails haben, mich aber nicht bei jeder einzelnen um einen eigenen Source kümmern.
nullfs to the rescue!
In die /etc/fstab.<meine Jail> kommt sowas:
/usr/src /usr/jails/example/usr/src nullfs ro 0 0
Natürlich nur sinnvoll wenn die Jails und den Host immer auf der selben Version laufen.
Native Jails
Noch benutze ich
einen Jail Manager (ezjail)
um mit Jails klar zu kommen.
Entwicklung ist eingeschlafen. Es gibt Alternativen, aber iocage ist wohl
inzwischen auch weg gefallen (FreeNAS Debian irgendwas?), bastille ist mir
zu “speziell”, pot weiß nicht, cbsd ¯\_(ツ)_/¯, dies, das, Ananas.
Außerdem Abhängigkeiten, Pakete, was weiß ich. </mimimi>
Sehr oft sieht man den Tipp:
Nutze die eingebauten Tools. Alles da, funktioniert immer.
Okay, ist eine Ansage. Machen wir.
Mein Setup ist ein Kind seiner Zeit - Inzwischen hat sich bei FreeBSD viel getan, die Zeit ist reif alles mal zu modernisieren!
Die Challenge/Gedanken/Ideen dabei:
-
Show must go on
- Kann ich parallel zu
ezjailtestweise mal eine native Jail laufen lassen?- Zwei, drei?
- Gleichzeitig
ezjail_enable="YES"undjail_enable="YES"?- Entspannt die Jails eine nach der anderen migrieren…
- Schaut gut aus!
- Kann ich parallel zu
-
Netzwerk
- Momentan habe ich:
lo1als clone vonlo0…- Ist gar nicht mal so geil.
- Inzwischen gibt es
VNET!- Verrenkungen in der
/etc/pf.conf?
- Verrenkungen in der
- Momentan habe ich:
-
ZFS
- Mach ich Thin oder Thick Jails?
- Vor/Nachteile?
- Bekommt man das automatisiert?
- Sowas wie die
ezjailflavors mit eingebaut? - Schreib ich mir dadurch meinen eigenen Jail Manager
- und mache alles noch schlimmer? 🙈
- Sowas wie die
- Wie strukturiert man dann die Snapshots? Falls.
- mountpoints
- Was wohin, und warum?
- Mach ich Thin oder Thick Jails?
-
Jail von
ezjailmigrieren- Oder lieber sauber neu aufsetzen?
- Daten migrieren…
- Kein Backup kein Mitleid.
-
Updates
- Wie geht?
- Tick Jail Update && Thin Jail neustart?!?
- Wie geht?
Demo: Thick Jail with VNET
Problem — von ezjail auf native Jails migrieren
(Hintergrund).
Mein Setup — Kind seiner Zeit und geht inzwischen besser.
Auf dieser Seite — wie kann ich (testweise) eine Thick Jail mit VNET
erstellen und diese (vorerst) parallel neben ezjail laufen lassen?
Netzwerk (bisher)
Meine Jails haben das Netzwerk bisher so aufgesetzt:
/etc/rc.conf vom Host:
cloned_interfaces="lo1"
ifconfig_lo1="inet 10.13.12.1/32"
ifconfig_lo1_ipv6="inet6 fd32:10:13:12::1 prefixlen 128"
In der /usr/local/etc/ezjail/some:
export jail_some_hostname="some"
export jail_some_ip="lo1|10.13.12.3,lo1|fd32:10:13:12::3"
Und die /etc/pf.conf (grob):
# public addresses
ip_em0_p4 = "1.2.3.4"
ip_em0_p6 = "1234:5678:90ab:cdef::1"
# jail addresses
ip_j_some4 = "10.13.12.3"
ip_j_some6 = "fd32:10:13:12::3"
…
# allow loopback traffic
set skip on { lo0, lo1 }
# outbound traffic from jails
nat pass on em0 inet from (lo1:network) to any -> $ip_em0_p4
nat pass on em0 inet6 from (lo1:network) to any -> $ip_em0_p6
# redirect traffic into jails
rdr pass log on em0 inet proto tcp from any to (em0:network) port http -> $ip_j_some4
rdr pass log on em0 inet6 proto tcp from any to (em0:network) port http -> $ip_j_some6
rdr pass log on em0 inet proto tcp from any to (em0:network) port https -> $ip_j_some4
rdr pass log on em0 inet6 proto tcp from any to (em0:network) port https -> $ip_j_some6
…
Funktioniert und tut was es soll.
Geht so, passt. Ist aber bisschen hämdsärmlig. vnet soll jetzt modern sein.
Storage
Die Jails von ezjail liegen unter /usr/jails, der Pool heißt tank.
Bei der Ordnerstruktur orientiere ich mich am Handbuch und erstelle mir Datasets:
zfs create tank/root/containers
zfs create tank/root/containers/classic
Schaut dann grob so aus:
…
tank 3.15T 3.69T 128K none
tank/root 3.15T 3.69T 151K /usr/jails
…
tank/root/containers 279K 3.69T 140K /usr/jails/containers
tank/root/containers/classic 140K 3.69T 140K /usr/jails/containers/classic
…
Thick Jail erstellen
Eigentlich geht es jetzt stumpf nach Handbuch…
Einmal das Userland bitte:
fetch https://download.freebsd.org/ftp/releases/amd64/amd64/`uname -r`/base.txz \
-o /usr/jails/containers/base.txz
Extrahieren:
tar -xf /usr/jails/containers/base.txz \
-C /usr/jails/containers/classic --unlink
Die timezone setzen:
cp /usr/jails/containers/classic/usr/share/zoneinfo/Europe/Berlin \
/usr/jails/containers/classic/etc/localtime
Als resolv.conf nutzen wir direkt die Server von Quad9:
cat << EOF > /usr/jails/containers/classic/etc/resolv.conf
nameserver 2620:fe::fe
nameserver 2620:fe::9
nameserver 149.112.112.112
nameserver 9.9.9.9
EOF
Haare schön machen:
freebsd-update -b /usr/jails/containers/classic fetch install
Netzwerk Config mit VNET
Die /etc/rc.conf wird erweitert:
cloned_interfaces="lo1 bridge0"
ifconfig_lo1="inet 10.13.12.1/32"
ifconfig_lo1_ipv6="inet6 fd32:10:13:12::1 prefixlen 128"
ifconfig_bridge0="inet 10.13.37.1/24"
ifconfig_bridge0_ipv6="inet6 fd32:10:13:37::1 prefixlen 64"
autobridge_interfaces="bridge0"
autobridge_bridge0="epair*a em0"
Sollte dann auch hoch kommen:
service bridge restart
service netif cloneup
Dazu in der /etc/pf.conf (grob):
…
# allow loopback traffic
set skip on { lo0, lo1, bridge0 }
# outbound traffic from jails
…
nat pass on em0 inet from (bridge0:network) to any -> $ip_em0_p4
nat pass on em0 inet6 from (bridge0:network) to any -> $ip_em0_p6
# redirect traffic into jails
…
rdr pass log on em0 inet proto tcp from any to (em0:network) port 4242 -> "10.13.37.23"
rdr pass log on em0 inet6 proto tcp from any to (em0:network) port 4242 -> "fd32:10:13:37:11::17"
…
Geht erstmal darum zu testen ob Trafic aus/in die Jail kommt. Deshalb fixe IP-Adressen und Ports… Wenn Test vorbei kommt das wieder weg!
pf neustarten, sich dadurch aus der ssh Session werfen, fluchen,
Tastatur & Monitor anschließen (falls geht) oder ganzen Server neustarten.
Ist mir noch nie passiert…
Jail Config
Hackerman fängt schon mal hart mit Templating an.
Dies hilft immer einheitlich zu bleiben. Auch wage ich den Versuch
auf so Sachen wie .include "/etc/jail.conf.d/*.conf"; o.Ä. zu verzichten –
Debugging wird einfacher wenn man nur ein File öffnen muss.
Das Resultat: Eine handverlesene Mixtur aus den Thick &
VNET Handbuch Seiten, der /var/run/jail.some.conf
und der Quelle Internet…
exec.start = "/bin/sh /etc/rc";
exec.stop = "/bin/sh /etc/rc.shutdown";
exec.consolelog = "/var/log/jail_console_${name}.log";
exec.system_user = "root";
exec.jail_user = "root";
exec.clean;
mount.fstab;
mount.devfs;
devfs_ruleset = 5;
path = "/usr/jails/containers/${name}";
mount.fstab = "/etc/fstab.jail.${name}";
allow.raw_sockets;
host.hostname = "${name}";
vnet;
vnet.interface = "${epair}b";
exec.prestart = "/sbin/ifconfig ${epair} create up";
exec.prestart += "/sbin/ifconfig ${epair}a descr jail=${name} up";
exec.prestart += "/sbin/ifconfig ${bridge} addm ${epair}a up";
exec.start += "/sbin/ifconfig ${epair}b inet ${ipv4} up";
exec.start += "/sbin/ifconfig ${epair}b inet6 ${ipv6} up";
exec.start += "/sbin/route -4 add default ${gw_4}";
exec.start += "/sbin/route -6 add default ${gw_6}";
exec.poststop += "/sbin/ifconfig ${bridge} deletem ${epair}a";
exec.poststop += "/sbin/ifconfig ${epair}a destroy";
classic {
$num = "23";
$hex = "17";
}
* {
$ipv4 = "10.13.37.${num}/24";
$ipv6 = "fd32:10:13:37:11::${hex}/64";
$gw_4 = "10.13.37.1";
$gw_6 = "fd32:10:13:37::1";
$epair = "epair${num}";
$bridge = "bridge0";
}
Pro Jail muss man nur $num und $hex definieren, Netzwerk Config in einer
Wildcard, ganz oben einheitliche Config. So der Plan…
-
exec.consolelog = "/var/log/jail_console_${name}.log";ezjailmacht/var/log/jail_${name}_console.log- somit wird neu/alt nicht clashen.
-
devfs_ruleset = 5;muss dasvnetruleset sein..- Das Default in
/etc/defaults/devfs.rulesist5:[devfsrules_jail_vnet=5]
- Das Default in
-
mount.fstab = "/etc/fstab.jail.${name}";ezjailmacht/etc/fstab.${name}- somit wird neu/alt nicht clashen.
- Wird erst für Thin Jails relevant
- Es reicht
echo "#" > /etc/fstab.jail.classic
-
vnet;&vnet.interface = "${epair}b";- Ist das Ziel der ganzen Aktion
- Für die Jail
classicwäre dasepair23b
-
exec.prestart(Auf dem Host)- Interfaces
epair23a&epair23bwerden erstellt epair23awird member derbridge0
- Interfaces
-
exec.start(In der Jail)epair23bbekommt IPv4 & IPv6 Addressen gesetzt- default routen werden gesetzt
Starten
Eigentlich haben wir alles die Jail sollte hoch kommen:
service jail onestart classic
In ezjail-admin list taucht classic nicht auf, jedoch in jls:
JID IP Address Hostname Path
…
5 10.13.12.3 some /usr/jails/some
…
10 classic /usr/jails/containers/classic
IP-Addresse hier nicht dabei! 🙀 Danke, VNET!
ifconfig zeigt epair23a und bridge0 hat dies als Member…
Testen
In die Jail kommt man stumpf mit jexec classic, oder vornehmer mit
jexec classic login -f root (motd, “You have mail.”).
Wir sollten die Devices /dev/zfs & /dev/pf
(wegen: devfs_ruleset = 5;) sehen.
Netzwerk geht?
drill aaaa wissen.der-beweis.de
drill a wissen.der-beweis.de
ping -6 -c 3 wissen.der-beweis.de
ping -c 3 wissen.der-beweis.de
;; ANSWER SECTION: & 0.0% packet loss ist das was wir sehen wollen! \o/
Wir haben Verbindung nach draußen.
Dann mal anders rum: nc -l 4242
Und von außen auf den Server: nc fetter.server.example.net 4242
Kryptische Nachricht erscheint. Also funktioniert auch! \o/
Fazit
Läuft!
Seitdem eine /etc/jail.conf existiert, wird pro einzelner ezjail
die startet eine neue Warning ausgegeben:
WARNING: /var/run/jail.some.conf is created and used for jail some.
…
/etc/rc.d/jail: WARNING: Per-jail configuration via jail_* variables is obsolete.
Please consider migrating to /etc/jail.conf.
Letzte Nachricht ist ja bereits bekannt - Was meinst du warum ich gerade den ganzen Aufwand treibe? 😅
Auch dauert das starten der Jails von ezjail jetzt gefühlt länger,
aber es funktioniert alles weiterhin.
ezjail parallel mit jail funktioniert auch:
sysrc ezjail_enable=YES ; sysrc jail_enable=YES
service ezjail restartstartet nur die eigenen Jails neu.service jail restartstoppt alle Jails, aber hängt beiezjaildie mountpoints nicht korrekt aus…
Also besser die Jails immer einzeln mit dem richtigen Tool neu starten.
- Jetzt funktionieren auch
service jail console classic&service jail console some.- Macht aber
lesskaputtWARNING: terminal is not fully functional- wtf?
- Macht aber
Was fehlt:
- Nur
/etc/resolv.conf&/etc/localtimehaben wir angefasst..- Irgendwas wie
ezjailflavor nachbauen?sysrc sendmail_enable=NONEoder ähnliche Späße laufen lassen..
- Irgendwas wie
Und weiter?
¯\_(ツ)_/¯
Demo: Thin Jails with nullfs
Problem — von ezjail auf native Jails migrieren
(Hintergrund).
Auf dieser Seite — wie kann ich Thin Jails mit VNET und nullfs von einer
Tick Jail erstellen und diese (vorerst) parallel neben ezjail laufen lassen?
Lasse die alte Thick Jail einfach mal so liegen, gehe aber von dieser Config aus, und erweitere die dann später.
Installation
Es geht streng nach Handbuch also erstelle ich mir Datasets:
zfs create tank/root/templates
zfs create tank/root/templates/13.4-RELEASE-base
Dann installieren wir mal ein älteres Release als vom Host:
fetch https://download.freebsd.org/ftp/releases/amd64/amd64/13.4-RELEASE/base.txz \
-o /usr/jails/templates/13.4-RELEASE-base.txz
tar -xf /usr/jails/templates/13.4-RELEASE-base.txz \
-C /usr/jails/templates/13.4-RELEASE-base --unlink
Bekannt von vorhin: timezone & resolv.conf:
cp /usr/jails/templates/13.4-RELEASE-base/usr/share/zoneinfo/Europe/Berlin \
/usr/jails/templates/13.4-RELEASE-base/etc/localtime
cat << EOF > /usr/jails/templates/13.4-RELEASE-base/etc/resolv.conf
nameserver 2620:fe::fe
nameserver 2620:fe::9
nameserver 149.112.112.112
nameserver 9.9.9.9
EOF
Updates! Damit die korrekten Updates für das Template installiert werden
muss man currently-running setzen:
freebsd-update -b /usr/jails/templates/13.4-RELEASE-base \
--currently-running 13.4-RELEASE \
fetch install
Skelett
Die Ordner die man in den Jails einzigartig (beschreibbar) haben möchte verschiebt man ins skeleton.
zfs create tank/root/templates/13.4-RELEASE-skeleton
mkdir -v /usr/jails/templates/13.4-RELEASE-skeleton/home
mkdir -v /usr/jails/templates/13.4-RELEASE-skeleton/usr
mv -v /usr/jails/templates/13.4-RELEASE-base/etc \
/usr/jails/templates/13.4-RELEASE-skeleton/etc
mv -v /usr/jails/templates/13.4-RELEASE-base/usr/local \
/usr/jails/templates/13.4-RELEASE-skeleton/usr/local
mv -v /usr/jails/templates/13.4-RELEASE-base/tmp \
/usr/jails/templates/13.4-RELEASE-skeleton/tmp
mv -v /usr/jails/templates/13.4-RELEASE-base/var \
/usr/jails/templates/13.4-RELEASE-skeleton/var
mv -v /usr/jails/templates/13.4-RELEASE-base/root \
/usr/jails/templates/13.4-RELEASE-skeleton/root
Hier gibts Beschwerde beim kopieren von /var/empty. Löschen geht nicht,
weil Berechtigungen.
Die /usr/jails/templates/13.4-RELEASE-skeleton/var/empty ist aber korrekt da.
Dennoch müssen wir das für den nächsten Schritt beheben:
chflags -R noschg /usr/jails/templates/13.4-RELEASE-base/var/empty
rmdir -v /usr/jails/templates/13.4-RELEASE-base/var/empty
rmdir -v /usr/jails/templates/13.4-RELEASE-base/var
Zurück in der Basis:
mkdir -v /usr/jails/templates/13.4-RELEASE-base/skeleton
ln -s skeleton/etc /usr/jails/templates/13.4-RELEASE-base/etc
ln -s ../skeleton/usr/local /usr/jails/templates/13.4-RELEASE-base/usr/local
ln -s skeleton/tmp /usr/jails/templates/13.4-RELEASE-base/tmp
ln -s skeleton/var /usr/jails/templates/13.4-RELEASE-base/var
ln -s skeleton/root /usr/jails/templates/13.4-RELEASE-base/root
ln -s skeleton/home /usr/jails/templates/13.4-RELEASE-base/home
Ein ls -l sollte dann so aussehen:
etc -> skeleton/etc
home -> skeleton/home
root -> skeleton/root
tmp -> skeleton/tmp
usr/local -> ../skeleton/usr/local
var -> skeleton/var
Thin Jails erstellen
Bitte recht freundlich:
zfs snapshot tank/root/templates/13.4-RELEASE-skeleton@base
Davon die Datasets für thin-demo & thin-test erstellen:
zfs clone tank/root/templates/13.4-RELEASE-skeleton@base \
tank/root/containers/thin-demo-data
zfs clone tank/root/templates/13.4-RELEASE-skeleton@base \
tank/root/containers/thin-test-data
Ein zfs list sollte nun grob so aussehen:
NAME USED AVAIL REFER MOUNTPOINT
…
tank 3.15T 3.69T 128K none
tank/root 3.15T 3.69T 151K /usr/jails
…
tank/root/containers 703M 3.69T 196M /usr/jails/containers
tank/root/containers/classic 507M 3.69T 490M /usr/jails/containers/classic
tank/root/containers/thin-demo-data 0B 3.69T 6.15M /usr/jails/containers/thin-demo-data
tank/root/containers/thin-test-data 0B 3.69T 6.15M /usr/jails/containers/thin-test-data
…
tank/root/some 1.49G 3.69T 797M /usr/jails/some
…
tank/root/templates 796M 3.69T 209M /usr/jails/templates
tank/root/templates/13.4-RELEASE-base 581M 3.69T 581M /usr/jails/templates/13.4-RELEASE-base
tank/root/templates/13.4-RELEASE-skeleton 6.15M 3.69T 6.15M /usr/jails/templates/13.4-RELEASE-skeleton
…
USED 0B — Schon gute Ansage 🙃
Konfiguration
Die /etc/jail.conf wird
auf Grundlage von vorhin erweitert —
Das Netzwerk Setup und die Jail Config von dort sollte da sein & funktionieren:
path = "/usr/jails/containers/${name}";
# falls noch nicht vorhanden
mount.fstab = "/etc/fstab.jail.${name}";
…
thin-demo {
$num = "13";
$hex = "d";
}
thin-test {
$num = "12";
$hex = "c";
}
Wir brauchen mountpoints und fstabs für thin-demo & thin-test:
mkdir -v /usr/jails/containers/thin-demo
mkdir -v /usr/jails/containers/thin-demo/skeleton
cat << EOF > /etc/fstab.jail.thin-demo
/usr/jails/templates/13.4-RELEASE-base /usr/jails/containers/thin-demo nullfs ro 0 0
/usr/jails/containers/thin-demo-data /usr/jails/containers/thin-demo/skeleton nullfs rw 0 0
EOF
mkdir -v /usr/jails/containers/thin-test
mkdir -v /usr/jails/containers/thin-test/skeleton
cat << EOF > /etc/fstab.jail.thin-test
/usr/jails/templates/13.4-RELEASE-base /usr/jails/containers/thin-test nullfs ro 0 0
/usr/jails/containers/thin-test-data /usr/jails/containers/thin-test/skeleton nullfs rw 0 0
EOF
Starten
Eigentlich haben wir alles die Jails sollten hoch kommen:
service jail start thin-test
Auf dem Host – mount checken:
tank/root/containers/thin-demo-data on /usr/jails/containers/thin-demo-data (zfs, local, nfsv4acls)
tank/root/templates/13.4-RELEASE-skeleton on /usr/jails/templates/13.4-RELEASE-skeleton (zfs, local, nfsv4acls)
tank/root/containers/thin-test-data on /usr/jails/containers/thin-test-data (zfs, local, nfsv4acls)
tank/root/templates/13.4-RELEASE-base on /usr/jails/templates/13.4-RELEASE-base (zfs, local, nfsv4acls)
…
/usr/jails/templates/13.4-RELEASE-base on /usr/jails/containers/thin-demo (nullfs, local, read-only, nfsv4acls)
/usr/jails/containers/thin-demo-data on /usr/jails/containers/thin-demo/skeleton (nullfs, local, nfsv4acls)
devfs on /usr/jails/containers/thin-demo/dev (devfs)
/usr/jails/templates/13.4-RELEASE-base on /usr/jails/containers/thin-test (nullfs, local, read-only, nfsv4acls)
/usr/jails/containers/thin-test-data on /usr/jails/containers/thin-test/skeleton (nullfs, local, nfsv4acls)
devfs on /usr/jails/containers/thin-test/dev (devfs)
In der Jail:
jexec thin-test login -f root
freebsd-version -ru
14.2-RELEASE
13.4-RELEASE-p2
touch /root/hering
touch /boot/test
touch: /boot/test: Read-only file system
cat /etc/motd
FreeBSD 14.2-RELEASE releng/14.2-n269506-c8918d6c7412 GENERIC
Welcome to FreeBSD!
…
- Neuer Kernel am Host, altes Userland in der Jail. So war das geplant!
- Nach
/etc,/home,/root,/tmp, … darf man schreiben, alles andere nicht… - Unbedingt checken, dass nicht
/etc,/home, … vom Host eingebunden wird. Hatte mich beim Symlink setzen von der Basejail ins Skeleton vertan. War das falsche/etcgemounted, eher fatal. Deshalb Blick in/etc/motd. - Netzwerk sollte™ funktionieren. Zum testen auf der anderen Seite nachsehen.
Wir haben den Ordner thin-test und das Dataset thin-test-data.
Der Hering ist also jetzt da:
/usr/jails/containers/thin-test/root/hering- Mountpoint der Jail - nur solange da wie die Jail läuft
/usr/jails/containers/thin-test-data/root/hering- Hier sind nur die Skeleton Ordner drin. Ist da, wo die Daten eigentlich liegen.
Fazit
Läuft!
- Irgendwie ist das anders als was
ezjailda macht.- Die Tage mal durch die Shell Scripte stöbern um mir da Anregungen zu holen.
- Auch mal nachschauen welche Ordner ich wirklich im Skeleton brauche.
- Nächster Schritt: Wie gehen Updates? Einfach neue Basejail bauen, und das im Mountpoint austauschen?
Und weiter?
¯\_(ツ)_/¯
Ezjail Host
Ich habe einen Server, der irgendwo im Rack verbaut ist, und dank FreeBSD schnurrt wie ein kleines Kätzchen.
Auf dieser Seite und deren Unterseiten halte ich fest, wie ich diesen eingerichtet habe.
Einerseits als Gedankenstütze, andererseits könnte dies hilfreich für andere sein.
Grundinstallation
Die Installation selbst ist nicht schwierig, allerdings sollte man sich vorab Gedanken über die Partitionierung machen, um in Zukunft nicht in Probleme zu laufen.
Da die Maschine im Rack steht, habe ich nur Remote-Zugriff darauf.
Somit habe ich mich entschlossen das Basissystem unverschlüsselt laufen zu lassen, der Bereich für die Jails ist verschlüsselt.
Hintergrund
Es sind 2 mal 3 TB Festplatten verbaut - somit lasse ich alles in einem RAID 1 laufen.
Am Ende soll pro Festplatte folgendes Partitionsschema entstehen:
| Partitionen | Größe | Typ | |
|---|---|---|---|
boot0 boot1 | 512K | boot | 2x einzeln |
sys0 sys1 | 80G | zfs | zfs mirror |
swap0 swap1 | 16G | swap | gmirror |
jail0 jail1 | Rest | zfs | zfs mirror |
Starten
Über die Remote Console (oder auf welchen Weg auch immer) den offiziellen FreeBSD Installer starten…
Wie gehabt installieren, bis man zum Schritt “Partitionierung” kommt. Dort Shell Partitioning auswählen.
Wenn man mit der Partitionierung in der Shell fertig ist, sollte unter /mnt
das Root Datei System eingebunden sein.
Konfiguration
Unter /tmp/bsd_install_… finden sich Templates, die später als
Konfiguration verwendet werden.
Benötigte Kernel-Module in der /tmp/bsd_install_boot/loader.conf:
zfs_load="YES"
geom_mirror_load="YES"
fdescfs_load="YES"
nullfs_load="YES"
geom_eli_load="YES"
crypto_load="YES"
aesni_load="YES"
Dann eine fstab unter /tmp/bsd_install_etc/fstab:
/dev/mirror/swap.eli none swap sw 0 0
Als letztes die /tmp/bsd_install_etc/rc.conf:
zfs_enable="YES"
Später brauchen wir noch ein paar Kernel-Module. Jetzt ist ein guter Zeitpunkt diese zu laden:
kldload zfs
kldload geom_mirror
kldload geom_eli
kldload crypto
kldload aesni
Partitionierung
Die beiden Festplatten wurden als /dev/ada0 und /dev/ada1 erkannt.
Als erstes wird die Partitionstabelle gelöscht:
dd if=/dev/zero of=/dev/ada0 bs=512 count=1
dd if=/dev/zero of=/dev/ada1 bs=512 count=1
Dann eine gpt Partitionstabelle anlegen:
gpart create -s gpt ada0
gpart create -s gpt ada1
Jetzt erstellen wir die Partitionen, wie oben in der Tabelle:
gpart add -s 512K -a 4k -t freebsd-boot -l boot0 ada0
gpart add -s 512K -a 4k -t freebsd-boot -l boot1 ada1
gpart add -s 80G -a 4k -t freebsd-zfs -l sys0 ada0
gpart add -s 80G -a 4k -t freebsd-zfs -l sys1 ada1
gpart add -s 16G -a 4k -t freebsd-swap -l swap0 ada0
gpart add -s 16G -a 4k -t freebsd-swap -l swap1 ada1
gpart add -a 4k -t freebsd-zfs -l jail0 ada0
gpart add -a 4k -t freebsd-zfs -l jail1 ada1
Es sollten unter /dev/gpt nun boot0, boot1, jail0, jail1,
swap0, swap1, sys0 und sys1 erscheinen.
Jetzt beide Festplatten parallel als Bootbar markieren - damit, falls eine Platte ausfällt, noch von der anderen gebootet werden kann:
gpart set -a bootme -i 1 ada0
gpart set -a bootme -i 1 ada1
Jetzt den System-Pool anlegen, zur Installation wird dieser unter /mnt
gemountet:
zpool create -R /mnt -O mountpoint=none system mirror gpt/sys0 gpt/sys1
zfs set compression=lz4 system
zfs set checksum=fletcher4 system
zfs create -o mountpoint=/ system/root
zfs create system/root/tmp
zfs create system/root/usr
zfs create system/root/usr/home
zfs create system/root/usr/local
zfs create system/root/usr/obj
zfs create system/root/usr/ports
zfs create system/root/usr/src
zfs create system/root/var
zfs create system/root/var/cache
zfs create system/root/var/db
zfs create system/root/var/log
zpool set bootfs=system/root system
Jetzt den Boot-Code installieren:
gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 ada0
gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 ada1
Swap
Für das Swap kommt ein geom mirror zum Einsatz:
gmirror label swap gpt/swap0 gpt/swap1
(Siehe dazu auch die /tmp/bsd_install_etc/fstab)
Jetzt ist alles fertig, somit können wir mit exit die Shell beenden,
und die Installation fertig stellen.
Nach Daumen drücken und einem Neustart geht es weiter mit dem anlegen eines Jail-Pools.
Jail-Pool
Nachdem die Grundinstallation fertig ist kann man sich um den Jail-Pool kümmern.
Die Schlüssel dazu sollten wir sicher ablegen (als root):
mkdir /root/keys
chmod go-rwx /root/keys
Schlüssel erzeugen:
dd if=/dev/random of=/root/keys/jail.key bs=256k count=1
Jetzt die Platten verschlüsseln (pro Festplatte nutze ich auch ein anderes Passwort…):
geli init -K /root/keys/jail.key -s 4096 -l 256 /dev/gpt/jail0
geli init -K /root/keys/jail.key -s 4096 -l 256 /dev/gpt/jail1
Die Platten einhängen:
geli attach -k /root/keys/jail.key /dev/gpt/jail0
geli attach -k /root/keys/jail.key /dev/gpt/jail1
Und nun den Pool erstellen:
zpool create -m none jail mirror gpt/jail0.eli gpt/jail1.eli
zfs set compression=lz4 jail
zfs set checksum=fletcher4 jail
zfs create -o mountpoint=/usr/jails jail/root
zfs create jail/root/flavours
zfs create jail/root/basejail
/root/keys ist in einem unverschlüsselten Bereich.
Die Schlüssel dort nicht einfach liegen lassen - da war die ganze Plattenverschlüsselung umsonst, wenn einem der Server aus dem Rack geschraubt wird.
Am besten ein offsite Backup machen (USB-Stick im Tresor oder so), und dann die Schlüssel löschen.
Zum automatischen Entsperren des Jail-Pools habe ich mir ein eigenes RC-Script geschrieben: geli_remote_unlock
Danach geht es weiter mit der Vorbereitung der Jails.
Vorbereitung der Jails
Zur Verwaltung der Jails setze ich ezjail ein.
Hintergrund
Der Server hat nach außen hin einen /64er Block IPv6 Adressen, jedoch
nur eine einzige IPv4 Adresse.
Somit kommt man nicht drum rum, den IPv4 Verkehr aus den Jails raus durch
ein NAT laufen zu lassen. Dies erledigt pf.
Für den Weg rein wird jeglicher Verkehr (auch mit pf) auf eine Jail
geleitet, in der ein Reverse Proxy läuft.
Vorwiegend sollen Webserver in den Jails laufen, somit wird jeglicher http und https Verkehr an die Reverse-Jail umgeleitet.
Ungefähr so:
+==Host==+
|
+-<-pf->-+
| |
+-----+ +-----+
| em0 | | lo0 |
+-----+ +-----+
| |
| +------+==Reverse-Proxy==+
+==Internet==+ |
+------+==Jail-A==+
|
+------+==Jail-B==+
|
+------+==...==+
Dies hat den Vorteil, dass ich die Terminierung der SSL-Zertifikate dem Reverse-Proxy überlassen kann.
Intern, zwischen den Jails wird dann nur IPv6 gesprochen.
Vorbereitung
Die Installation von ezjail ist recht einfach:
cd /usr/ports/sysutils/ezjail
make install
Pro Jail möchte ich ein eigenes ZFS Dataset haben, somit kommt in die
/usr/local/etc/ezjail.conf (weiter unten) folgendes:
ezjail_use_zfs="YES"
ezjail_use_zfs_for_jails="YES"
ezjail_jailzfs="jail/root"
Ggf. ezjail_jailzfs anpassen, es sollte ein Dataset sein, dass
auf /usr/jails zeigt:
zfs list -r jail
NAME USED AVAIL REFER MOUNTPOINT
jail 224K 2.56T 88K none
jail/root 224K 2.56T 88K /usr/jails
(Dieses Dataset habe ich mir bei der Installation erzeugt. Mehr Details dort nachlesen.)
Danach in der /etc/rc.conf ezjail selbst aktivieren:
ezjail_enable="YES"
Weil wir gerade dabei sind, ein zweites Loopback Interface einrichten, um den Traffic der Jails von dem Loopback Traffic des Hosts zu separieren:
cloned_interfaces="lo1"
Damit das mit dem Traffic in die Jails rein funktioniert muss man noch Forwarding aktivieren:
gateway_enable="YES"
ipv6_gateway_enable="YES"
Danach kann man lo1 und ezjail manuell starten:
service netif cloneup
service ezjail start
Für das Forwarding braucht es noch zwei sysctls.
Unter /etc/sysctl.conf:
net.inet.ip.forwarding=1
net.inet6.ip6.forwarding=1
Bootstrapping
Auf meinem Server baue ich mir die Pakete selbst.
Ich könnte mir das Base Jail mit ezjail-admin update -bp erstellen,
doch dann wird world auf nur einem Core gebaut, und das dauert…
-bruftmake buildworld; make installworldauf, um die Base Jail zu bauen.-pgibt der Base Jail mittelsportsnapeinen ports tree mit.
Um das ein bisschen zu beschleunigen mache ich das hier:
cd /usr/src
make buildworld -j8
ezjail-admin update -ip
-iruft nurmake installworldauf (haben world ja eben erst gebaut).-j8(von make) sollte der Anzahl von Cores entsprechen..
Siehe an, der Aufwand hat sich gelohnt:
zfs list -r jail
NAME USED AVAIL REFER MOUNTPOINT
jail 1.18G 2.56T 88K none
jail/root 1.18G 2.56T 104K /usr/jails
jail/root/basejail 1.15G 2.56T 1.15G /usr/jails/basejail
jail/root/newjail 26.4M 2.56T 26.4M /usr/jails/newjail
Als nächsten Schritt kümmern wir uns um die Jail Flavours.
Jail Flavours
Flavours sind das beste Feature seit geschnitten Brot - diese nehmen einem immer wiederkehrende Aufgaben beim Erstellen einer neuen Jail ab.
Ich habe einen Großteil aus dem example Ordner übernommen, und mir einen
flavour mit dem Namen self erstellt:
find /usr/jails/flavours/self
/usr/jails/flavours/self
/usr/jails/flavours/self/usr
/usr/jails/flavours/self/usr/home
/usr/jails/flavours/self/usr/home/user
/usr/jails/flavours/self/usr/home/user/.ssh
/usr/jails/flavours/self/usr/home/user/.ssh/authorized_keys
/usr/jails/flavours/self/usr/local
/usr/jails/flavours/self/usr/local/etc
/usr/jails/flavours/self/usr/local/etc/sudoers
/usr/jails/flavours/self/etc
/usr/jails/flavours/self/etc/resolv.conf
/usr/jails/flavours/self/etc/rc.conf
/usr/jails/flavours/self/etc/make.conf
/usr/jails/flavours/self/etc/periodic.conf
/usr/jails/flavours/self/etc/rc.d
/usr/jails/flavours/self/etc/rc.d/ezjail_flavour
/usr/jails/flavours/self/pkg
-
Darauf achten, dass die Rechte passend gesetzt sind (
home;~/.ssh; executable flags; …). -
Die
resolv.confwurde vom Host kopiert. -
Die
make.confist an die des Hosts angelehnt. -
Nach langem debugging habe ich folgendes herausgefunden:
-
/pkgwird bei der Installation gesucht, und nicht gefunden. Deshalb ist das mit im Flavour, und wird im Startup Script wieder gelöscht (Dies tritt nur bei Verwendung von Flavours auf, ohne wird nicht nach/pkggesucht… wtf?!?). -
Das Flavour Script darf keine Punkte im Dateinamen haben. Scheint ein recht neues Verhalten zu sein (Sehr gut, dass das Beispiel eben welche hat…).
-
Mein ezjail_flavour Script schaut in etwa so aus:
#!/bin/sh
#
# BEFORE: DAEMON
# PROVIDE: ezjail.self.config
#
# customized ezjail flavour
. /etc/rc.subr
name=ezjail_flavour
start_cmd=flavour_setup
flavour_setup() {
# Remove traces of ourself
rm -f "/etc/rc.d/ezjail_flavour"
###
# Timezone - Uhr auf Kartoffel stellen
ln -s /usr/share/zoneinfo/Europe/Berlin /etc/localtime
###
# Groups
pw groupadd -q -n user
###
# User
#
# Den SHA512 Hash kann man sich entweder aus der
# /etc/master.passwd ziehen, oder manuell generieren:
# python -c 'import crypt; print crypt.crypt("password", "$6$saltSALTsaltSALT$")'
# Daran denken, der Salt hat 16 Stellen
echo -n "$6$saltSALTsaltSALT$/AvblmZPXYozjA6BrX3kTfO7hmUjwG9RkmHZwXkE9zD2sRY1Y6RT809yDoBG0ZgjDENLFTbipaDgtqYf.gnnY0" |\
pw useradd \
-n user -u 1001 -c 'Awesome Jail User' \
-d /usr/home/user -m \
-s /bin/csh \
-g user -G wheel \
-H 0
###
# symlink user directories
ln -s /usr/home /home
###
# Files
chown -R user:user /usr/home/user
###
# Packages
[ -d /pkg ] && rm -rfv /pkg
###
# remove adjkerntz from crontab
cat /etc/crontab | grep -E -v -i "(adjkerntz|adjust the time zone)" > /etc/crontab.temp
mv /etc/crontab.temp /etc/crontab
}
run_rc_command "$1"
Das eigene Flavour in der /usr/local/etc/ezjail.conf als
Standard definieren:
ezjail_default_flavour="self"
Sind die Flavours fertig, sollten wir uns um die Firewall und das Routing kümmern.
Firewall
Einerseits um das System abzudichten, und um andererseits den Traffic an die
korrekten Stellen weiterzuleiten setze ich pf ein.
Hier meine /etc/pf.conf. Diese enthält mehr als nur für die Jails benötigt
wird, aber ich finde, so werden alle Zusamenhänge besser ersichtlich:
# interfaces
if_ext = "em0"
if_lo0 = "lo0"
if_lo1 = "lo1"
# externe Adressen des Hosts
ip_ext4 = "11.22.33.44"
ip_ext6 = "2a11:22:33:44::1"
# interne Adressen der Reverse-Proxy Jail
ip_jailproxy4 = "10.23.42.2"
ip_jailproxy6 = "fd10:23:42:23::2"
# Dienste die am Host laufen (ssh & mosh)
inbound_tcp = "{ ssh }"
inbound_udp = "{ 60000:60010 }"
# Dienste die in den Jails laufen (web)
j_inbound_tcp = "{ http, https }"
#j_inbound_udp = "{}"
# Dienste die der Host erreichen darf
outbound_tcp = "{ ssh, domain, http, https, ftp }"
outbound_udp = "{ domain, ntp }"
# ICMP Konfiguration
icmp4_types = "{ echoreq, unreach }"
icmp6_types = "{ echoreq, echorep, unreach, toobig, timex, routersol, routeradv, neighbrsol, neighbradv, redir }"
# Jeglichen Traffic auf den Loopbacks erlauben
set skip on $if_lo0
set skip on $if_lo1
# Kein Reject schicken, nur Droppen
set block-policy drop
# Einkommenden Traffic defragmentieren und normalisieren
scrub in on $if_ext all fragment reassemble
# Traffic aus den Jails raus geht durch ein NAT
nat pass on $if_ext inet from $if_lo1:network to any -> $ip_ext4
nat pass on $if_ext inet6 from $if_lo1:network to any -> $ip_ext6
# Traffic in die Jails rein weiterleiten
rdr pass on $if_ext inet proto tcp from any to $if_ext:network port $j_inbound_tcp -> $ip_jailproxy4
#rdr pass on $if_ext inet proto udp from any to $if_ext:network port $j_inbound_udp -> $ip_jailproxy4
rdr pass on $if_ext inet6 proto tcp from any to $if_ext:network port $j_inbound_tcp -> $ip_jailproxy6
#rdr pass on $if_ext inet6 proto udp from any to $if_ext:network port $j_inbound_udp -> $ip_jailproxy6
# Default - Alles blockieren
block log all
# Ping Pong
pass inet proto icmp all icmp-type $icmp4_types keep state
pase inet6 proto icmp6 al icmp6-type $icmp6_types keep state
# Der Host darf Dienste außerhalb erreichen
pass out proto tcp to any port $outbound_tcp keep state
pass out proto udp to any port $outbound_udp keep state
# Dienste auf dem Host dürfen von außen erreicht werden
pass in log proto tcp to any port $inbound_tcp keep state
pass in log proto udp to any port $inbound_udp keep state
Mit dem schönen Kommando pfctl -vnf /etc/pf.conf kann man überprüfen,
ob das Config-File korrekt ist.
Zum neustarten von pf empfiehlt sich folgender Trick:
service pf restart ; sleep 120 && service pf stop
Sollte man sich beim Starten vom Host aussperren, dann wird nach 2 Minuten die Firewall wieder abgeschalten - Somit kann man sich dann noch wenigstens wieder einloggen, um den Fehler zu beheben…
Vor dem Starten von pf in der /etc/rc.conf diese aktivieren:
pf_enable="YES"
pf_rules="/etc/pf.conf"
pf_flags=""
pflog_enable="YES"
pflog_logfile="/var/log/pflog"
pflog_flags=""
Weil wir schon dabei sind am Netzwerk zu frickeln, sollten wir uns jetzt darum kümmern, dass alle Dienste nicht global auf Wildcard Adressen lauschen. Ein immer wiederkehrender Kandidat ist z.B. NTP.
Und nun geht es endlich daran, die ersten Jails zu erstellen: Eine Webserver Jail und die Reverse-Proxy Jail.
Webserver Jail
Das Erstellen einer Jail geht recht einfach:
ezjail-admin create demo "lo1|10.23.42.5,lo1|fd10:23:42:23::5"
Die IP-Adressen stammen aus dem Bereich, den ich beim konfigurieren der Firewall für die Jails vorgesehen habe.
Die IPv4 Adresse ist dank Reverse-Proxy Jail nicht zwingend nötig, allerding kann es sein, dass man von der Jail aus IPv4-only Hosts erreichen möchte, deshalb habe ich eine vergeben.
Falls noch Dienste laufen, die auf Wildcard Adressen lauschen meckert ezjail (zu recht) rum. Dies sollte man abstellen und dann von vorne beginnen (z.B. Anleitung für NTPd).
Da wir nur einen kurzen Namen gesetzt haben, passen wir den Hostnamen in
der /usr/local/etc/ezjail/demo an:
export jail_demo_hostname="demo.example.com"
Nachdem man unter /usr/jails/demo verifiziert hat, dass der
Flavour korrekt funktioniert hat, kann
man die Jail starten:
ezjail-admin start demo
Um in die Jail zu gelangen gibt es den console Befehl:
ezjail-admin console demo
Als erstes sollte man die /etc/hosts innerhalb der Jail
glatt ziehen:
::1 localhost
127.0.0.1 localhost
fd10:23:42:23::5 demo.example.com
10.23.42.5 demo.example.com
NGINX
nginx aus den Quellen zu bauen ist recht einfach:
cd /usr/ports/www/nginx
make config-recursive install clean
Hierbei habe ich alles auf Standard gelassen, jedoch das MAIL_MODULE
abgewählt.
In der /etc/rc.conf wird nginx aktiviert:
nginx_enable="YES"
Auf FreeBSD erwartet nginx seine Konfigurationsdatei unter
/usr/local/etc/nginx/nginx.conf.
Die Standardeinstellungen würden schon genügen, allerdings will ich wie immer meine Extrawurst haben und alles selbst konfigurieren…
Die Anforderungen sind folgende:
- Wir hängen hinter einem Reverse-Proxy, deshalb:
- müssen wir uns nicht um SSL kümmern
- kann man es sich leisten auf IPv4 zu verzichten
- kann man die meisten (Security-) Header weglassen
- braucht man auch kein GZip
Somit habe ich /usr/local/etc/nginx/ mal wegkopiert und mir ein
eigenes Set an Konfiguration erstellt:
find /usr/local/etc/nginx -type f
/usr/local/etc/nginx/sites/demo.example.com.conf
/usr/local/etc/nginx/conf/general.conf
/usr/local/etc/nginx/mime.types
/usr/local/etc/nginx/nginx.conf
-
/usr/local/etc/nginx/mime.typeswurde wieder hin kopiert… -
/usr/local/etc/nginx/nginx.conf
user www;
pid /var/run/nginx.pid;
worker_processes auto;
worker_rlimit_nofile 65535;
events {
multi_accept on;
worker_connections 65535;
}
http {
charset utf-8;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
server_tokens off;
log_not_found off;
types_hash_max_size 2048;
client_max_body_size 64M;
# MIME
include mime.types;
default_type application/octet-stream;
# logging
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log warn;
# load configs
include sites/*.conf;
}
/usr/local/etc/nginx/conf/general.conf
# dot files
location ~ /\. {
deny all;
}
# assets, media
location ~* \.(?:css(\.map)?|js(\.map)?|jpe?g|png|gif|ico|cur|heic|webp|tiff?|mp3|m4a|aac|ogg|midi?|wav|mp4|mov|webm|mpe?g|avi|ogv|flv|wmv|svgz?|ttf|ttc|otf|eot|woff2?)$ {
expires max;
access_log off;
}
/usr/local/etc/nginx/sites/demo.example.com.conf
server {
listen [fd10:23:42:23::5]:80;
server_name demo.example.com;
root /usr/local/www/demo.example.com;
# logging
access_log /var/log/nginx/demo.example.com.access.log;
error_log /var/log/nginx/demo.example.com.error.log warn;
include conf/general.conf;
}
Danach noch eine /usr/local/www/demo.example.com/index.html anlegen und
dieser die Gruppe www zuweisen (auch dem Ordner darüber).
Dann nginx mittels service nginx start erstmals starten.
Vom Host aus kann man überprüfen, ob alles geklappt hat:
echo "GET /" | nc fd10:23:42:23::5 80
Dies sollte den Inhalt der index.html ausgeben.
Damit man von außen auch die Webseite betrachten kann, fehlt ein letzter Baustein: Die Reverse-Proxy Jail.
Reverse-Proxy Jail
Das erstellen der Jail ist gleich zu dem wie in der Webserver Jail.
Natürlich aber mit anderen IP-Adressen (/etc/hosts der Jail):
::1 localhost
127.0.0.1 localhost
fd10:23:42:23::5 reverse.example.com
10.23.42.5 reverse.example.com
Hier ist eine IPv4 Adresse leider zwingend nötig, es gibt nach wie vor Leute, die dieses steinalte Protokoll nutzen…
NGINX
Innerhalb der Jail bauen wir uns nginx:
cd /usr/ports/www/nginx
make config-recursive install clean
Die Standardeinstellungen sind fein.
Danach wird in der /etc/rc.conf der Webserver aktiviert:
nginx_enable="YES"
Auch hier habe ich mir einen eigenen Satz an Konfigurationsdateien gebastelt:
find /usr/local/etc/nginx -type f
/usr/local/etc/nginx/mime.types
/usr/local/etc/nginx/nginx.conf
/usr/local/etc/nginx/conf/general.conf
/usr/local/etc/nginx/conf/proxy.conf
/usr/local/etc/nginx/conf/letsencrypt.conf
/usr/local/etc/nginx/sites/_sinkhole.conf
/usr/local/etc/nginx/sites/demo.example.com.conf
/usr/local/etc/nginx/sites/www.example.com.conf
-
/usr/local/etc/nginx/mime.typesstammt aus der Standardkonfiguration. -
/usr/local/etc/nginx/nginx.conf
user www;
pid /var/run/nginx.pid;
worker_processes auto;
worker_rlimit_nofile 65535;
events {
multi_accept on;
worker_connections 65535;
}
http {
charset utf-8;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
server_tokens off;
log_not_found off;
types_hash_max_size 2048;
client_max_body_size 64M;
# MIME
include mime.types;
default_type application/octet-stream;
# logging
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log warn;
# SSL
ssl_session_timeout 10m;
ssl_session_cache shared:SSL:10m;
ssl_session_tickets off;
# Diffie-Hellman parameter for DHE ciphersuites
ssl_dhparam /usr/local/etc/nginx/dhparam.pem;
# intermediate configuration
ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3;
ssl_ciphers ECDHE-RSA-AES256-GCM-SHA512:DHE-RSA-AES256-GCM-SHA512:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-SHA384;
ssl_ecdh_curve secp384r1;
ssl_prefer_server_ciphers on;
# OCSP Stapling
ssl_stapling on;
ssl_stapling_verify on;
resolver 208.67.222.222 208.67.220.220 valid=300s;
resolver_timeout 5s;
# Security Headers
add_header Strict-Transport-Security "max-age=63072000; includeSubDomains; preload";
add_header X-Frame-Options DENY;
add_header X-Content-Type-Options nosniff;
add_header X-XSS-Protection "1; mode=block";
# load configs
include sites/*.conf;
}
/usr/local/etc/nginx/conf/general.conf
# security headers
add_header X-Frame-Options "SAMEORIGIN" always;
add_header X-XSS-Protection "1; mode=block" always;
add_header X-Content-Type-Options "nosniff" always;
add_header Referrer-Policy "no-referrer-when-downgrade" always;
add_header Content-Security-Policy "default-src * data: 'unsafe-eval' 'unsafe-inline'" always;
# dot files
location ~ /\. {
deny all;
}
# gzip
gzip on;
gzip_vary on;
gzip_proxied any;
gzip_comp_level 6;
gzip_types text/plain text/css text/xml application/json application/javascript application/xml+rss application/atom+xml image/svg+xml;
/usr/local/etc/nginx/conf/proxy.conf
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Port $server_port;
proxy_cache_bypass $http_upgrade;
/usr/local/etc/nginx/conf/letsencrypt.conf
# ACME-challenge
location ^~ /.well-known/acme-challenge/ {
root /usr/local/www/_letsencrypt;
}
/usr/local/etc/nginx/sites/_sinkhole.conf
server {
listen 10.23.42.2:443 ssl http2;
listen [fd10:23:42:23::2]:443 ssl http2;
server_name _;
# SSL
ssl_certificate /usr/local/etc/letsencrypt/live/example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/example.com/privkey.pem;
ssl_trusted_certificate /etc/letsencrypt/live/example.com/chain.pem;
return 444;
}
# HTTP redirect
server {
listen 10.23.42.2:80;
listen [fd10:23:42:23::2]:80;
server_name _;
return 444;
}
/usr/local/etc/nginx/sites/demo.example.com
server {
listen 10.23.42.2:443 ssl http2;
listen [fd10:23:42:23::2]:443 ssl http2;
server_name demo.example.com;
# SSL
ssl_certificate /usr/local/etc/letsencrypt/live/example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/example.com/privkey.pem;
ssl_trusted_certificate /etc/letsencrypt/live/example.com/chain.pem;
# logging
access_log /var/log/nginx/demo.example.com.access.log;
error_log /var/log/nginx/demo.example.com.error.log warn;
# reverse proxy
location / {
proxy_pass http://[fd10:23:42:23::5]:80;
include conf/proxy.conf;
}
include conf/general.conf;
}
# HTTP redirect
server {
listen 10.23.42.2:80;
listen [fd10:23:42:23::2]:80;
server_name demo.example.com;
include conf/letsencrypt.conf;
location / {
return 301 https://demo.example.com$request_uri;
}
}
/usr/local/etc/nginx/sites/www.example.com
server {
listen 10.23.42.2:443 ssl http2;
listen [fd10:23:42:23::2]:443 ssl http2;
server_name www.example.com;
# SSL
ssl_certificate /usr/local/etc/letsencrypt/live/example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/example.com/privkey.pem;
ssl_trusted_certificate /etc/letsencrypt/live/example.com/chain.pem;
# logging
access_log /var/log/nginx/www.example.com.access.log;
error_log /var/log/nginx/www.example.com.error.log warn;
# reverse proxy
location / {
proxy_pass http://[fd10:23:42:23::3]:80;
include conf/proxy.conf;
}
include conf/general.conf;
}
# HTTP redirect
server {
listen 10.23.42.2:80;
listen [fd10:23:42:23::2]:80;
server_name www.example.com;
include conf/letsencrypt.conf;
location / {
return 301 https://www.example.com$request_uri;
}
}
Let’s Encrypt
Erstmal den certbot installieren:
cd /usr/ports/security/py-certbot
make config-recursive install clean
Dann basteln wir uns Diffie-Hellman Keys:
openssl dhparam -dsaparam -out /usr/local/etc/nginx/dhparam.pem 4096
Wir brauchen einen Ordner für die ACME Challenge:
mkdir /usr/local/www/_letsencrypt
chown www:www /usr/local/www/_letsencrypt
Jetzt basteln wir uns ein Zertifikat:
certbot certonly --webroot \
-d example.com -d www.example.com -d demo.example.com \
--email letsencrypt@example.com \
--webroot-path /usr/local/www/_letsencrypt \
--non-interactive \
--agree-tos \
--force-renewal
Tarsnap
Es gilt wie immer folgender Spruch: Kein Backup - kein Mitleid!
Ich habe mich deshalb für Tarsnap entschieden.
Nachdem man sich auf der Webseite ein Konto angelegt hat, wird auf dem Host der offizielle Client installiert:
cd /usr/ports/sysutils/tarsnap
make install clean
Danach wird ein Blick in die /usr/local/etc/tarsnap.conf geworfen, und
sichergestellt das der Ort für das keyfile und des cachedirs passt.
Und nun sollte man sich ein keyfile erstellen:
tarsnap-keygen \
--keyfile /root/tarsnap-machine.key \
--user user@example.org \
--machine machine
Diesen Key sollte man sich unbedingt irgendwo anders speichern, sonst kommt man nicht mehr an das Backup ran!
Ausdrucken, USB-Stick im Bankschließfach, irgendwas anderes kreatives …
Sollte man in der Firewall den ausgehenden Traffic filtern, so muss man sich dazu ein Loch bohren:
- Outbound TCP Traffic auf Port
9279erlauben
Die Netzwerk Dokumentation hat genaueres dazu.
Grundlegende Befehle
Archiv erzeugen:
tarsnap -c \
-f name-$(date "+%Y-%m-%d_%H-%M-%S") \
/what/to/backup
Vorhandene Archive einsehen:
tarsnap --list-archives | sort
Ein Archiv löschen:
tarsnap -d \
-f name-YYYY-mm-dd_HH-MM-SS
Inhalt eines Archivs anzeigen lassen:
tarsnap -tv \
-f name-YYYY-mm-dd_HH-MM-SS
Ein Archiv wiederherstellen:
mkdir -p /tmp/restore
cd /tmp/restore
tarsnap -x \
-f name-YYYY-mm-dd_HH-MM-SS
Who needs backups, if you can have restore?
Tarsnapper
Meine Motivation auf Dauer eine ganze Menge wirrer Shell-Scripte zu pflegen ist recht gering. Einfache Dinge gehen noch, aber dann noch ein Generationenprinzip zu implementieren ist mir zu aufwändig.
Nach ein länglicher Recherche und Querlesen von Code habe ich mich für Tarsnapper entschieden.
Das gibt es in den Ports - solange Python 2 noch die Standard Version auf FreeBSD ist nutze ich diese (gibt auch einen Port für Python 3):
cd /usr/ports/sysutils/py-tarsnapper
make install clean
Die Konfiguration dazu habe ich unter /usr/local/etc/tarsnapper.yaml
abgelegt und schaut in etwa so aus:
deltas: 1d 7d 30d
target: /machine/$name-$date
jobs:
etc:
sources:
- /etc
- /usr/local/etc
excludes:
- /etc/defaults
fixed:
source: /tmp/tarsnap-fixed
exec_before: |
/bin/mkdir -p /tmp/tarsnap-fixed;
/bin/cat /etc/fstab > /tmp/tarsnap-fixed/fstab;
/sbin/dmesg > /tmp/tarsnap-fixed/dmesg;
/sbin/gpart show > /tmp/tarsnap-fixed/gpart_show;
/sbin/zfs list > /tmp/tarsnap-fixed/zfs_list;
/sbin/zfs mount > /tmp/tarsnap-fixed/zfs_mount;
/sbin/zpool list > /tmp/tarsnap-fixed/zpool_status;
exec_after: /bin/rm -rf /tmp/tarsnap-fixed;
db-jail:
source: /tmp/tarsnap-db-jail
exec_before: |
/bin/mkdir -p /tmp/tarsnap-db-jail;
/usr/sbin/jexec -U postgres database pg_dumpall > \
/tmp/tarsnap-db-jail/dump-jail.sql;
exec_after: /bin/rm -rf /tmp/tarsnap-db-jail;
Ist ein Serviervorschlag, und kann nach Belieben angepasst werden.
-
etcJob: Einfach nur die Konfigurationen - Nothing special there -
fixedJob: Die FreeBSD Handbuchseite zu Backups empfiehlt, ein paar grundlegende Daten zur Recovery bereit zu halten:- Partitionslayout
- Mountpoints
- Genutzte Treiber
- … alles was hilfreich zur Systemwiederherstellung ist
Die
exec_beforeundexec_afterDirektiven werden laut Quellcode direkt an eine Shell weitergeleitet. Damit alles lesbar bleibt nutze ich einen Block Skalar (|).Ich habe konsequent volle Pfade für die Befehle genutzt, damit es keine Probleme gibt, wenn das ganze in der Crontab läuft.
-
db-jailJob: Habe PostgreSQL innerhalb einer Jail am laufen. Ein Backup von Datenbanken im Betrieb empfiehlt sich nicht, also nutze ichpg_dumpallum alles zu exportieren.Um von außen an die Jail ranzukommen nutze ich
jexec.
Als letzten Schritt wird das ganze noch in die Crontab geworfen:
23 5 * * * /usr/local/bin/tarsnapper -c /usr/local/etc/tarsnapper.yaml -q - make
Updates
Hier ein kleiner Überblick, wie man das System auf dem aktuellsten Stand hält.
Ports updaten
Um sich das Userland (das man sich aus den Ports baut) aktuell zu halten sollte man öfters folgendes Schema durchgehen.
Auf dem Host werden erstmal die Ports aktualisiert:
portsnap fetch update
Danach sollte man sich mit portmaster alle Ports neu bauen lassen:
portmaster -abd
Sollte man portmaster noch nicht installiert haben, so findet man diesen
unter ports-mgmt/portmaster.
Jetzt sind die Jails an der Reihe. Die Ports für die Jails aktualisiert man so:
ezjail-admin update -P
Danach in die Jail wechseln, und dann darin portmaster -abd laufen lassen.
Ggf. in der Jail vorher portmaster bauen
(Ist bei mir immer das erste Paket, dass ich in einer Jail baue).
System updaten
Es gilt zunächst den Order /usr/src mit dem aktuellsten Stand zu versorgen.
Die offizielle Anleitung spricht immer davon das per svn zu machen,
finde ich aber eher nicht so prall.
Somit nutze ich:
freebsd-update fetch
Es kann nie schaden einen Blick in die Anweisungen
unter /usr/src/UPDATING zu werfen!
Danach alles neu bauen:
cd /usr/src
make -j8 buildworld
make -j8 kernel
Für diese Schritte muss man ein bisschen Zeit mitbringen.
Zwölf Kannen Kaffee und drei Mettbrötchen später ist es dann soweit!
Danach alles installieren und updaten:
make installworld
mergemaster -Ui
Wichtig: Kein -j bei make installworld verwenden.
Es sei denn man möchte sich die Installation kaputt machen!
mergemaster ist ein kleines Biest, aber wenn man sich oft genug
dort durchgequält hat kommt man damit klar :)
Basejail
Bevor man weiter macht sollte man alle Jails stoppen:
service ezjail stop
Danach geht es daran die Basejail zu updaten:
ezjail-admin update -i
-iruft nurmake installworldauf (haben world eben erst gebaut)
Jetzt heißt es Daumen drücken, und die schöne Uptime killen:
shutdown -r now
Sollte man beim neustarten nicht seinen Server verloren haben kann man dann noch aufräumen:
cd /usr/src
make clean
Netzwerk-Anhangs-Speicher
Ich habe einen kleinen Würfel, hinten mit Netzwerk-Buchse & Strom, innen sind fünf Festplatten. Feine Sache, das.
Hier ein paar Notizen zur Installation.
Vorbereitung
Das USB-Image schreiben (hier z.B. von einem Mac aus):
sudo dd if=FreeBSD-11.0-RELEASE-amd64-memstick.img of=/dev/rdisk4 bs=1m conv=sync
Davon booten, den Installer abbrechen, und in die Live-Shell wechseln.
Als root einloggen, und erstmal Module nachladen:
kldload geom_eli zfs aesni
Partitionieren
Das System soll eigenständig laufen können, die Daten sollen aber trotzdem verschlüsselt sein.
Weiterhin sollen die Festplatten alle gleich partitioniert sein, da diese im Verbund laufen.
Das System wird natürlich mit UEFI aufgesetzt - modern, modern!
Dies ergibt dann sechs Partitionen pro Platte…
- zwei Boot-Partitionen (efi & gpt)
- eine Partition für den
zfs mirrorbootpool (unverschlüsselt -/boot) - eine Swap-Partition (verschlüsselt)
- eine Partition für den
raidz2-Pool zroot (unverschlüsselt - System/) - eine Partition für den
raidz2-Pool tank (verschlüsselt - Daten/tank)
Zurecht finden:
-
Ein
gpart showlistet die Platten mit ihren Partitionen sowie deren Start und End-Sektoren. -
Ein
camcontrol devlistzeigt die Herstellerdaten der Platten, und deren Device-Files (z.B./dev/ada0). -
camcontrol identify ada0zeigt noch mehr Informationen zur Platte an.
Frisch ans Werk:
foreach i ( 0 1 2 3 4 )
foreach? gpart create -s GPT "ada$i"
foreach? gpart add -t efi -l "efiboot$i" -s 800K "ada$i"
foreach? gpart add -t freebsd-boot -l "gptboot$i" -s 512K "ada$i"
foreach? gpart add -t freebsd-zfs -l "boot$i" -s 2G -a 4K "ada$i"
foreach? gpart add -t freebsd-swap -s 2G -a 4K "ada$i"
foreach? gpart add -t freebsd-zfs -l "zroot$i" -s 15G -a 4K "ada$i"
foreach? gpart add -t freebsd-zfs -l "tank$i" -a 4K "ada$i"
foreach? end
- Die Blockgrößen werden auf
4Kfestgezurrt (gpart ... -a 4K)
Hinweis:
foreachfunktioniert natürlich nur in der csh (und Varianten).
Als nächstes kommt der Bootloader:
foreach i ( 0 1 2 3 4 )
foreach? dd if=/boot/boot1.efifat of="/dev/ada${i}p1"
foreach? gpart bootcode -b /boot/pmbr -p /boot/gptboot -i 2 "ada$i"
foreach? end
- Der EFI-Loader wird in die erste Partition geschrieben (
dd ...). - Die GPT-Boot-Partitionen bekommen ihren Bootstrap-Code verpasst
(
gpart bootcode ... -i 2).
An dieser Stelle kann man bereits einmal neu starten, um zu testen, ob der Bootloader geladen wird, und soweit alles funktioniert. Muss man aber nicht.
Jetzt sind die Pools dran:
Damit das System später Platz hat, legen wir den RAIDz2 Pool zroot an:
zpool create -o cachefile=/var/tmp/zpool.cache \
-o altroot=/mnt zroot raidz2 \
/dev/gpt/zroot0.nop /dev/gpt/zroot1.nop \
/dev/gpt/zroot2.nop /dev/gpt/zroot3.nop \
/dev/gpt/zroot4.nop
Wir erstellen davor aber noch einen Mountpoint in den wir schreiben dürfen:
mkdir /tmp/zroot
zpool create -m /tmp/zroot zroot raidz2 ada0p3 ada1p3 ada2p3 ada3p3 ada4p3
Dann werden die Mountpoints für das System eingetragen:
zfs create zroot/home
zfs create zroot/root
zfs create zroot/tmp
zfs create zroot/usr
zfs create zroot/usr/home
zfs create zroot/usr/ports
zfs create zroot/usr/src
zfs create zroot/var
zfs create zroot/var/audit
zfs create zroot/var/crash
zfs create zroot/var/log
zfs create zroot/var/mail
zfs create zroot/var/tmp
Access Time ausschalten:
zfs set atime=off zroot
Installieren
Sind die Platten soweit partitioniert, wird das System entpackt:
tar -xvf /usr/freebsd-dist/base.txz -C /tmp/zroot
tar -xvf /usr/freebsd-dist/kernel.txz -C /tmp/zroot
tar -xvf /usr/freebsd-dist/doc.txz -C /tmp/zroot
tar -xvf /usr/freebsd-dist/lib32.txz -C /tmp/zroot
Jetzt wird konfiguriert! In die /tmp/zroot/boot/loader.conf kommt:
geom_eli_load="YES"
zfs_load="YES"
aesni_load="YES"
vfs.root.mountfrom="zfs:zroot/ROOT/default"
autoboot_delay="3"
Die /tmp/zroot/etc/fstab wird erstellt:
/dev/ada0p2.eli none swap sw 0 0
/dev/ada1p2.eli none swap sw 0 0
/dev/ada2p2.eli none swap sw 0 0
/dev/ada3p2.eli none swap sw 0 0
/dev/ada4p2.eli none swap sw 0 0
zroot / zfs rw,noatime 0 0
zroot/root /root zfs rw,noatime 0 0
zroot/home /home zfs rw,noatime 0 0
zroot/tmp /tmp zfs rw,noatime 0 0
zroot/usr /usr zfs rw,noatime 0 0
zroot/usr/home /usr/home zfs rw,noatime 0 0
zroot/usr/ports /usr/ports zfs rw,noatime 0 0
zroot/usr/src /usr/src zfs rw,noatime 0 0
zroot/var /var zfs rw,noatime 0 0
zroot/var/audit /var/audit zfs rw,noatime 0 0
zroot/var/crash /var/crash zfs rw,noatime 0 0
zroot/var/log /var/log zfs rw,noatime 0 0
zroot/var/mail /var/mail zfs rw,noatime 0 0
zroot/var/tmp /var/tmp zfs rw,noatime 0 0
Any & All
any() & all() sind durchaus praktisch.
Doch etwas sollte man beachten.
- Um zu wissen ob eine oder alle Bedingungen wahr sind, werden alle evaluiert.
- Das ist anders, als wenn man diese mit
and&orverknüpft
Wir haben diese Funktionen:
def tt(msg):
print('t', msg)
return True
def ff(msg):
print('f', msg)
return False
Verknüpft man diese mit and so sieht man, dass die Kette wie erwartet
am vorletzten Element abbricht:
>>> tt(1) and tt(2) and ff(3) and tt(4)
t 1
t 2
f 3
False
all() führt jedoch alle Funktionen in der Kette aus:
>>> all([tt(1), tt(2), ff(3), tt(4)])
t 1
t 2
f 3
t 4
False
Dreht man die Funktionen um, und nutzt das or, so wird wieder
vorzeitig abbgebrochen:
>>> ff(1) or ff(2) or tt(3) or ff(4)
f 1
f 2
t 3
True
any() evaluiert aber wieder alle Elemente:
>>> any([ff(1), ff(2), tt(3), ff(4)])
f 1
f 2
t 3
f 4
True
Merke
Es ist nicht möglich Funktionen mit any() oder all() zu verketten, in
der Hoffnung dass die gesamte Kette abbricht, wenn eine Funktionen
fehlschlägt..
Die Begründung ist recht simpel: Beide Funktionen bekommen ein
iterable (hier eine Liste) übergeben.
Um die Liste erst mal erstellen zu können, muss der Interpreter alle Elemente evaluieren. Dies sieht man so:
>>> [tt(1), ff(2)]
t 1
f 2
[True, False]
Man kann all() & any() dennoch dazu überreden vorzeitig abzubrechen, man
muss aber ein bisschen improvisieren:
>>> all(f(n) for n, f in enumerate([tt, tt, ff, tt], start=1))
t 1
t 2
f 3
False
Dict Magic
if-elif-else Kaskade
Altes Problem, kennt man:
>>> if var == 'one':
... res = 1
... elif var == 'two':
... res = 2
... elif var == 'three':
... res = 3
... else:
... res = -1
Doch schon mal daran gedacht, das alles ein bisschen kompakter zu formulieren?
>>> res = dict(
... one=1,
... two=2,
... three=3,
... ).get(var, -1)
List Magic
Head, Tail
Altes Problem, geht man zumeist so an:
>>> l = list(range(10))
>>> l
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> head, tail = l[0], l[1:]
>>> head
0
>>> tail
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Nach PEP 3132 wird das alles viel eleganter:
>>> head, *tail = list(range(10))
>>> head
0
>>> tail
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Was noch so geht
Zum Beispiel beim Iterieren über eine Liste von Tupeln das letzte Element extra behandeln:
>>> l = list((x, x+x, x*x) for x in range(5))
>>> l
[(0, 0, 0), (1, 2, 1), (2, 4, 4), (3, 6, 9), (4, 8, 16)]
>>> for *head, last in l:
... print(last, '->', head)
...
0 -> [0, 0]
1 -> [1, 2]
4 -> [2, 4]
9 -> [3, 6]
16 -> [4, 8]
Flatten
Verschachtelte Listen lassen sich durch eine List-Comprehension auflösen:
>>> ll = [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
>>> [fl for at in ll for fl in at]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Das ganze ist aber nicht Speichereffizient.
Wenn man über die Elemente in den Listen der Liste iterieren muss, greift man
auf die itertools zurück:
>>> from itertools import chain
>>> ll = [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
>>> cl = chain.from_iterable(ll)
>>> cl
<itertools.chain object at 0x10a8b5b00>
>>> for c in cl:
... print(c)
...
0
1
2
[...]
Achtung. Es handelt sich hier um einen Iterator. Wenn versucht wird mehrmals darüber zu iterieren, wird das nichts.
>>> ll = [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
>>> cl = chain.from_iterable(ll)
>>> list(cl)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list(cl)
[]
Verschachtelt iterieren
Das ganze lässt sich aber auch dazu nutzen, mehrere for-loops abzukürzen:
>>> res = []
>>> for x in [0, 1, 2, 3, 4]:
... for y in [5, 6, 7, 8, 9]:
... res.append((x, y, x+y, x*y))
>>> res
[(0, 5, 5, 0), (0, 6, 6, 0), (0, 7, 7, 0), ...]
… wird somit zu:
>>> nres = [(x, y, x+y, x*y) for x in [0, 1, 2, 3, 4] for y in [5, 6, 7, 8, 9]]
>>> nres
[(0, 5, 5, 0), (0, 6, 6, 0), (0, 7, 7, 0), ...]
>>> assert res == nres
Little Helpers
Es gibt eine Menge von Tools die in Python geschrieben sind, um das Leben beim Programmieren oder generell einfacher zu machen.
Auf einem frischen System läuft bei mir erst mal das hier:
pip3 install -U \
bpython \
black \
isort \
pyflakes \
pylint \
pyyaml \
sphinx \
watchdog
Und dann hab ich noch ein paar Aliasse, die recht praktisch sind:
.pyc und __pycache__ entfernen:
pyc() {
find . \
-name '*.pyc' -delete -print -o \
-name '__pycache__' -delete -print
}
Der HTTP Server:
serve_http() { python -m http.server "$@"; }
Sendmail emulieren:
serve_smtp() { python -m smtpd -n -c DebuggingServer "localhost:${1-"2525"}"; }
Wo liegen denn die installierten Module?
alias python_libdir='python -c "from distutils.sysconfig import get_python_lib; print(get_python_lib());"'
bpython
Interaktiver Python Interpreter, mit:
- Syntax Highlighting!
- Autocomplete!
- Auto Indentation!
- Rollback!
- Buzzwords!
Ist sehr hilfreich!
black
Formatiert den Quellcode so dass es eindeutig und lesbar bleibt.
isort
Sortiert automatisch die import-Statements.
Wandert rekursiv durchs Package… Es ist sehr gut!
watchdog
Der kleine Dackel steckt seine Nase zwischen alle Files auf die man ihn los lässt, und bellt bei Änderungen…
Beispiel:
Bei Änderungen an den source-files im Ordner ./src,
ruft Waldi make build auf:
watchmedo shell-command ./docs \
--recursive \
--ignore-directories \
--drop \
--patterns="*.cpp;*.hpp" \
--command="make build"
Lambdas
Lambdas sind anonyme Funktionen in Python.
Man kann folgende Funktion…
def dx(x, y):
return (x, y, x+y, x*y)
auch kompakter hinschreiben:
lx = lambda x, y: (x, y, x+y, x*y)
>>> lx(0, 1); dx(0, 1)
(0, 1, 1, 0)
(0, 1, 1, 0)
>>> lx(1, 2); dx(1, 2)
(1, 2, 3, 2)
(1, 2, 3, 2)
>>> lx(2, 3); dx(2, 3)
(2, 3, 5, 6)
(2, 3, 5, 6)
>>> for n in range(1337+1):
... assert lx(n, n+1) == dx(n, n+1)
Aber…
PEP 8#programming-recommendations ist da unmissverständlich:
Always use a def statement instead of an assignment statement that binds a lambda expression directly to an identifier.
Also, wozu der ganze Aufwand?
Es gibt Funktionen, die als Parameter wiederum eine Funktion übergeben bekommen. Dies ist an manchen Stellen recht praktisch.
Zum Beispiel nuzen wir eine Klasse als Container, um Dinge darin zu speichern:
class C:
def update(self, func, key):
setattr(self, key, func(
getattr(self, key, None)
))
>>> c = C()
>>> c.holy = 'hand grenade'
>>> c.num = 23
>>> vars(c)
{'holy': 'hand grenade', 'num': 23}
Die update-Funktion macht folgendes:
>>> c.update(str.upper, 'holy')
>>> vars(c)
{'holy': 'HAND GRENADE', 'num': 23}
Besteht nun Bedarf an spezielleren Operationen, kommt das lambda ins
Spiel:
>>> c.update(lambda n: n*n, 'num')
>>> vars(c)
{'holy': 'HAND GRENADE', 'num': 529}
Vorsicht
Lambdas sind abhänig von ihrem jeweiligen Kontext:
>>> y = 23
>>> f = lambda x: x+y
>>> f(23)
46
>>> y = 42
>>> f(23)
65
Der Fix hierzu wäre es, das y in den Scope des lambdas beim Erstellen
zu übernehmen:
>>> y = 23
>>> f = lambda x, y=y: x+y
>>> f(23)
46
>>> y = 42
>>> f(23)
46
Wie man sieht, dies alles führt zu unleserlichen Code, bis hin zu schweren Verletzungen beim Debuggen..
Snake Mutants from Outer Space
Python gliedert seine Objekte in mutable und immutable Typen.
In der Dokumentation Kapitel 3 Data Model steht:
The value of some objects can change.
Objects whose value can change are said to be mutable; objects whose value is unchangeable once they are created are called immutable.
Alles klar, soweit. Weiter im Text:
(The value of an immutable container object that contains a reference to a mutable object can change when the latter’s value is changed; however the container is still considered immutable, because the collection of objects it contains cannot be changed. So, immutability is not strictly the same as having an unchangeable value, it is more subtle.)
Au weia, klingt gefährlich – In der Tat ist dies auch ein Quell von vielen Missverständnissen und Bugs. Deshalb dieser Artikel.
Noch schnell den Rest:
An object’s mutability is determined by its type; for instance, numbers, strings and tuples are immutable, while dictionaries and lists are mutable.
Leider gibt es keine offizielle Tabelle, was nun welcher Typ ist.
Deshalb hier eine von mir zusammenrecherchierte (ohne Gewähr):
| ✄ | immutable | mutable |
|---|---|---|
object | ✐ | |
byte array | ✐ | |
bytes | ✌︎ | |
complex | ✌︎ | |
dict | ✐ | |
float | ✌︎ | |
frozen set | ✌︎ | |
int | ✌︎ | |
list | ✐ | |
long | ✌︎ | |
named tuple | ✌︎ | |
range | ✌︎ | |
set | ✐ | |
str | ✌︎ | |
tuple | ✌︎ |
Das Problem
Objekte die immutable sind verhalten sich so:
>>> x = 42
>>> y = x
>>> x += 23
>>> x
65
>>> y
42
Bei mutable schaut das aber so aus:
>>> x = list()
>>> y = x
>>> x.append('spam')
>>> y.append('eggs')
>>> x
['spam', 'eggs']
>>> y
['spam', 'eggs']
Bitte was? - In der Tabelle steht, dass mutable Typen nur Container Objekte betreffen (also Objekte, die andere Objekte beinhalten).
Das liegt daran, wie Python intern die Daten speichert und erreichbar macht. Die Details dazu können andere besser erklären, deshalb sind diese Artikel sehr empfohlen:
- Facts and myths about Python names and values von Ned Batchelder
- Is Python call-by-value or call-by-reference? Neither. von Jeff Knupp
Und im Handbuch:
- 4.6.1. Common Sequence Operations
- 4.6.2. Immutable Sequence Types
- 4.6.3. Mutable Sequence Types
Was ist nun oben passiert? Da die Liste mutable ist, wird in der
Zeile y = x nicht der Inhalt, sondern die Adresse von x nach y
zugewiesen..
Dies Bedeutet:
mutable Objekte
- sind Container mit vielen anderen Sachen drin ☞ speicherintensiv.
- werden nur einmal im Speicher gehalten
- jede Referenz ist sozusagen nur ein Pointer darauf
immutable Objekte
- werden bei jeder Zuweisung neu erstellt
- können also auch einen “Pointer” (auf ein anderes immutable Objekt) sein.
- Wird jedoch der Wert geändert (Zuweisung ☞ Objekt wird neu erstellt), zeigt die Variable auf das neue Objekt.
Hier ein paar Beispiele wie einem das alles auf die Füße fallen kann, und wie man damit umgeht.
Listen
Eine leicht andere Variante des Beispiels von oben:
>>> x = y = ['spam', 'eggs']
>>> x.append('bacon')
>>> y.append('chips')
>>> x
['spam', 'eggs', 'bacon', 'chips']
>>> y
['spam', 'eggs', 'bacon', 'chips']
Listen muss man also referenzfrei kopieren. Das geht auf mehrere Arten:
>>> x = ['spam', 'eggs']
>>> y = list(x)
>>> z = z[:]
>>> x.append('bacon')
>>> y.append('chips')
>>> z.append('sausage')
>>> x
['spam', 'eggs', 'bacon']
>>> y
['spam', 'eggs', 'chips']
>>> z
['spam', 'eggs', 'sausage']
Egal ob list() oder [:] - beide iterieren über den Inhalt und
erzeugen so neue Referenzen.
Verschachtelte Listen
Zum Beispiel brauchen wir eine Liste mit drei unter-Listen. Hämdsärmlich geht man da ran und wundert sich über folgende Ausgabe:
>>> x = [[]] * 3
>>> x
[[], [], []]
>>> x[0].append('spam')
>>> x[1].append('eggs')
>>> x
[['spam', 'eggs'], ['spam', 'eggs'], ['spam', 'eggs']]
Ja klar, wir erstellen ja eine Liste mit drei Zeigern auf das selbe innere Listen-Objekt. Das löst man das so:
>>> x = [[] for _ in range(3)]
>>> x
[[], [], []]
>>> x[0].append('spam')
>>> x[1].append('eggs')
>>> x
[['spam'], ['eggs'], []]
Durch das iterieren (for _ in range()) werden drei neue, innere Listen
erstellt. Hat mir schon mal tagelang Kopfzerbrechen bereitet.
Dictionaries & Sets
Das ist eigentlich der Klassiker:
>>> x = dict()
>>> y = x
>>> y
{}
>>> x.update(spam='eggs')
>>> x
{'spam': 'eggs'}
>>> y
{'spam': 'eggs'}
Was also tun? Dictionaries & Sets haben eine copy()-Methode! :
>>> x = dict(spam='eggs')
>>> y = x.copy()
>>> x.update(fish='chips')
>>> x
{'fish': 'chips', 'spam': 'eggs'}
>>> y
{'spam': 'eggs'}
Objekte
Was tun mit sonstigen Objekten?
>>> class Cls:
... pass
...
>>> x = Cls()
>>> y = x
>>> x.spam = 'eggs'
>>> y.crispy = 'bacon'
>>> vars(x)
{'spam': 'eggs', 'crispy': 'bacon'}
>>> vars(y)
{'spam': 'eggs', 'crispy': 'bacon'}
Na Toll. Eigenen Code kann man ändern, damit es klappt, ansonsten kann
man copy.copy oder copy.deepcopy einsetzen:
>>> x = Cls()
>>> y = copy(x)
>>> x.spam = 'eggs'
>>> y.crispy = 'bacon'
>>> vars(x)
{'spam': 'eggs'}
>>> vars(y)
{'crispy': 'bacon'}
Weird Python
Hier sammelt sich ein bisschen Zeug, aus den Kategorien kurioses und skurriles..
Alles was der Interpreter zwar verarbeitet, wohl aber unter Schmerzen.
Quine
Ein Quine ist ein Programm, das eine Kopie seines Quelltextes als Ausgabe schreibt.
Mit ein bisschen Schummeln bekommt man das sehr kompakt hin:
print(open(__file__).read())
Aber warte mal, den eigenen Quellcode nur ausgeben ist ein bisschen wenig..
Schon mal was von Rekursion gehört?
exec(open(__file__).read())
IncrementalDecoder.__init__(self, errors)
RecursionError: maximum recursion depth exceeded
🤓
Sleepsort
Sleepsort ist ein recht eleganter Sortier-Algorithmus, besticht vor allem durch seine Geschwindigkeit:
#!/usr/bin/env python3
from multiprocessing import Pool
from random import shuffle
from sys import argv
from time import sleep
def align(num):
sleep(num)
print(num)
def crowd():
try:
max_num = int(argv[-1])
except ValueError:
max_num = 23
numbers = list(range(max_num))
shuffle(numbers)
return numbers
if __name__ == '__main__':
NUMBERS = crowd()
with Pool(len(NUMBERS)) as group:
group.map(align, NUMBERS)
ESP-01s
Hier ein paar Aufzeichnungen zu meinen esp8266 ESP-01s Modulen.
-
Breakout-Boards
- Sind sehr praktisch (mitbestellen!), man will nicht ständig 8 einzelne Dupont-Stecker umstecken.
-
USB-Seriell UART
- Geht eigentlich jeder beliebige, hauptsache man findet Treiber..
- Ich habe unterschiedliche:
CP2102 den Treiber dazu gibts mit Homebrew und es gibt genug Strom für alle!
PL2303 liefert leider zu wenig Strom zum flashen des ESPs, aber es gibt inzwischen auch einen Treiber mittels Homebrew.
-
Strom
- Verbrauch: 250mA bis 750mA (bei WiFi).
- Liefert entweder der UART, schöner ist jedoch immer eine externe Stromversorgung!
-
Baud
-
Der Bootloader spricht wohl
76800Baud (2 * 38400).- Alternativ
57600Baud versuchen. - Funktioniert bei mir beides nicht kann also nichts zum AT-Modus sagen.
- Alternativ
-
Zum Flashen entweder
9600oder115200Baud.
-
Flash-Only Schaltung
Eine statische Schaltung zum Flashen baut man sich so:
| ESP | UART |
|---|---|
TXD | RXT |
RXD | TXD |
EN | 3.3 |
3.3 | 3.3 |
GND | GND |
GP0 | GND |
RST | GND |
GP2 | offen |
-
RSTnachGNDläuft über einen Taster, als Reset Schalter.- Kann man sich zur Not auch sparen.
-
Darauf achten, dass der UART genug Strom liefert
- Falls nicht, externe Stromversorgung nutzen!
-
Nach dem Flashen funktioniert die Serielle Console nur einmal, und nur so lange bis man Reset drückt.
-
Das Breadboard verteilt eigentlich nur
GNDund3.3weiter. -
Der Taster zieht
RSTaufGND. -
Die eingebaute LED auf dem ESP sollte beim Reset kurz leuchten.
RXDam UART auch (“ready” Prompt des Bootloaders).
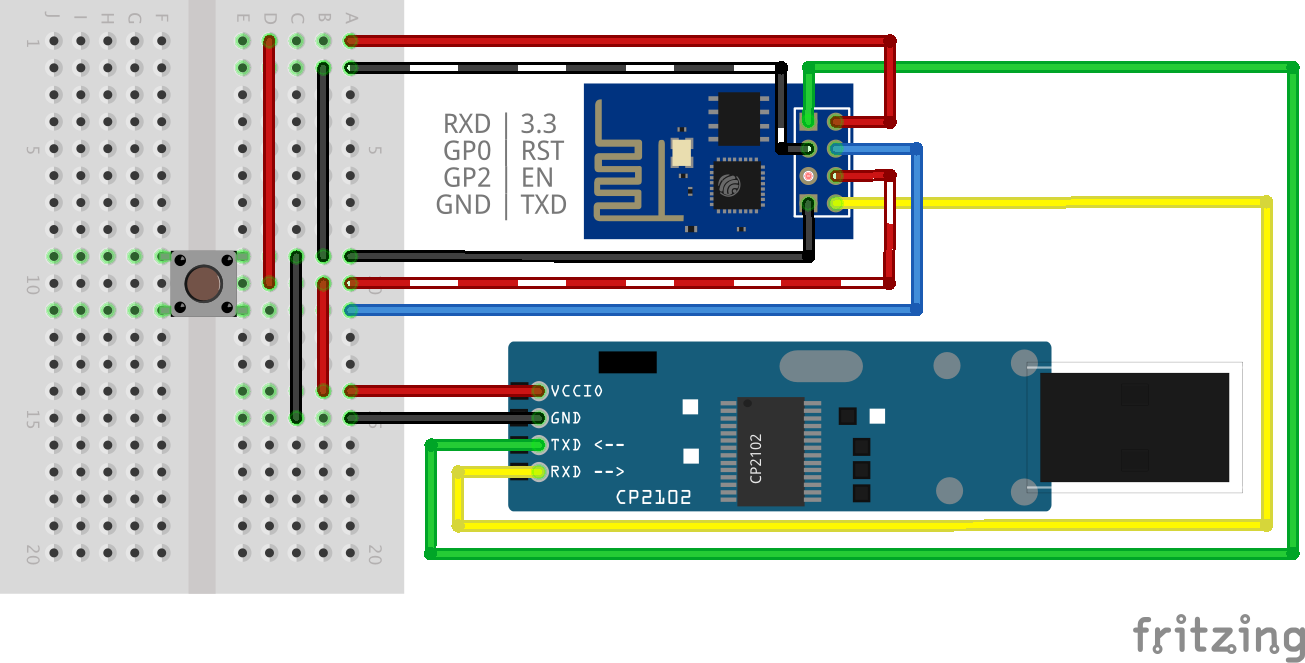
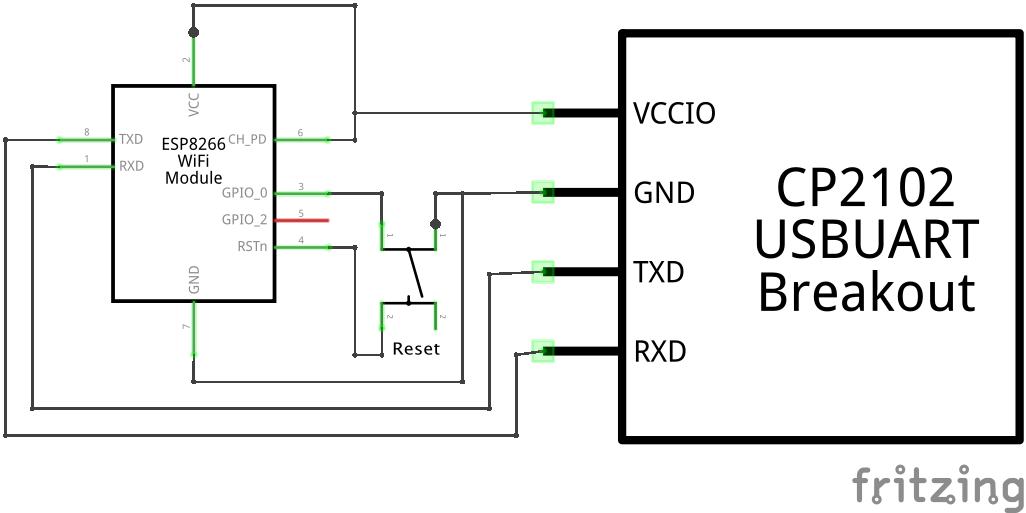
Development Schaltung
Den ESP immer umstecken ist aufwändig, lieber noch einen zweiten Taster und einen Pull-Up Widerstand dazu:
| ESP | ESP => Board | Board <= UART | UART |
|---|---|---|---|
TXD | RXT | ||
RXD | TXD | ||
EN | <-R | R<- | 3.3 |
3.3 | 3.3 | ||
GND | GND | ||
GP0 | Flash -/- | zur Schaltung | |
GP0 | Flash --- | GND | |
RST | Reset -/- | <-R | |
RST | Reset --- | GND | |
GP2 | zur Schaltung |
-
Als Pull-Up Widerstand: 10kΩ
ENundRSTwerden jetzt darüber hochgezogen.
-
Der Flash Taster schaltet den
GP0zwischen der eigenen Schaltung undGNDum. -
Zeichen
- Schalter
-/-offen---geschlossen
- Widerstand
R<-rein<-Rraus
- Schalter
-
Konami Code zum Flashen
- Reset drücken & halten.
- Flash drücken & halten.
- Reset loslassen & Upload starten.
- Wenn der Upload begonnen hat, kann man Flash loslassen.
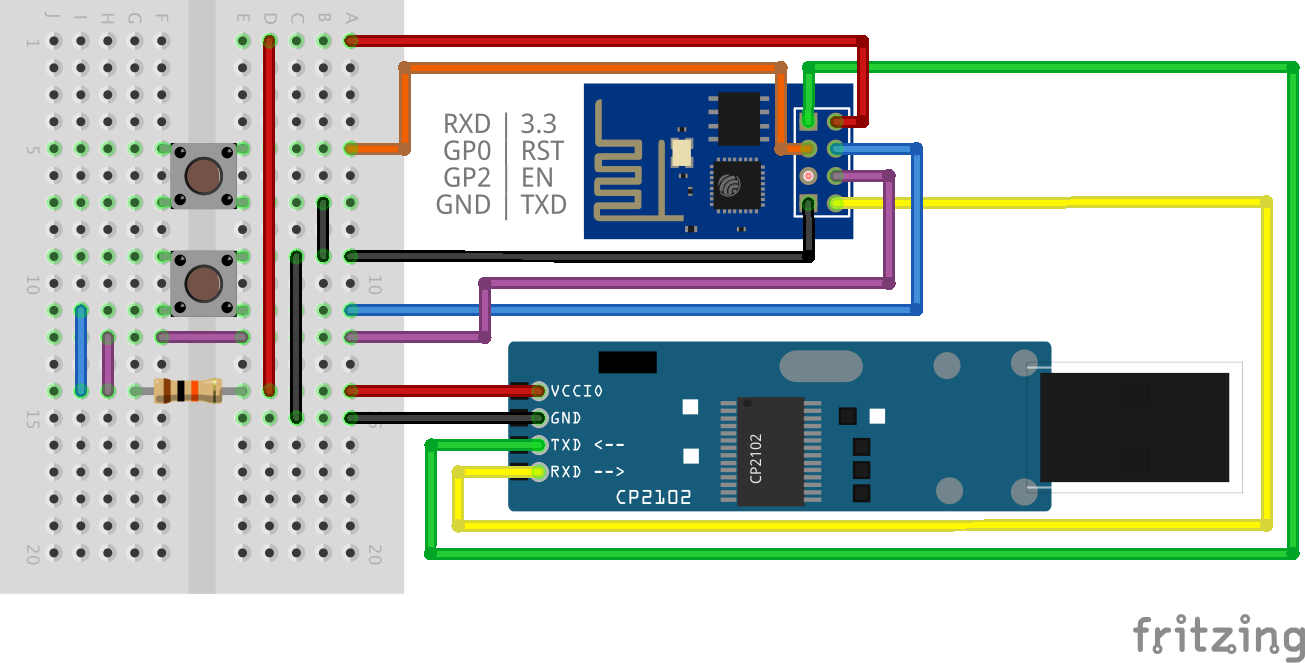
FritzBox DynDNS
Solange wir noch mit IPv4, NAT und automatisch wechselnden IP-Adressen
zu kämpfen haben muss man DynDNS nutzen…
Placeholder
Hier eine Liste der Templates die in der FritzBox möglich sind:
| Wert | URL-Placeholder |
|---|---|
| Nutzername | <username> |
| Passwort | <pass> / <passwd> |
| Domain Name | <domain> |
IPv4 Adresse | <ipaddr> |
IPv6 Adresse | <ip6addr> |
IPv6 Präfix | <ip6lanprefix> |
| Dual-Stack | <dualstack> |
Angeblich geht auch noch base64:
<b64>daten zum encodieren</b64>
Update
Update-URL für schokokeks.org:
https://dyndns.schokokeks.org/nic/update?myip=<ipaddr>&myipv6=<ip6addr>
Obacht
Leider ist der DynDNS Client auf der FritzBox nicht gerade gut..
Habe beobachtet, dass dieser nur läuft, wenn die DSL-Verbindung neu aufgebaut wird.
Bei einer nächtlichen Neuvergabe der IP4-Adresse / dem IPV6 Präfix (looking at you, shitty provider) macht die FritzBox kein DynDNS Update!
Somit zeigen die Adressen im DNS irgendwo hin, nur nicht da wo man wirklich erreichbar ist.
Das macht den DynDNS Client auf der FritzBox unbrauchbar.
Wenn es also irgendwie geht was eigenes laufen lassen.
Weiterhin bin ich über diesen Blog-Artikel gestolpert (Archive) der noch ein paar weitere Probleme schildert.
Deployment via Git-Hook
Diese Seite hier wird mittels mdBook gepflegt, und liegt in einem (bare) Git-Repository (auf dem selben Server).
Da Mensch faul ist, will man nicht immer die Doku per Hand bauen, und dann manuell hochladen.
Mittels post-receive
Git-Hook
kann man den Webserver dazu veranlassen dies nach jedem Push
automatisch zu tun.
#!/bin/sh
# repository location
HOOK_DIR="$(cd "$(dirname "$0")" && pwd || exit 2)"
REPO_DIR="$(realpath "$HOOK_DIR")"
# public target folder
OUTDIR="/webserver/pfad/zur/doku"
# path to the cargo binaries
CARGO="$HOME/.cargo/bin"
# create temporary directories
BUILDDIR=$(mktemp -d -t wissen_build.XXXXX)
CLONEDIR=$(mktemp -d -t wissen_clone.XXXXX)
# clone the bare repository
if ! (
mkdir -p "$OUTDIR" &&
git clone "$REPO_DIR" "$CLONEDIR"
); then
echo "clone failed"
exit 3
fi
# build the documentation
if ! (
cd "$CLONEDIR" &&
PATH="$CARGO:$PATH" mdbook build --dest-dir "$BUILDDIR" "$CLONEDIR"
); then
echo "build failed"
exit 2
fi
# move the files around and clean up
if ! (
rm -rf "$OUTDIR" &&
cp -a "$BUILDDIR/html" "$OUTDIR" &&
chmod -v 755 "$OUTDIR" &&
rm -rf "$BUILDDIR" "$CLONEDIR"
); then
echo "file handling failed"
exit 1
fi
echo "deployment successful"
exit 0
Zugegeben - das Script ist sehr schlicht, funktioniert jedoch recht zuverlässig. Die einfachsten Lösungen sind doch immernoch die besten :)
SSH Config
~/.ssh/config – Feine Sache das…
Globbing
Host one two three
Hostname %h.local
IdentityFile ~/.ssh/home_25519
User user
Host *example.net
Hostname host.example.net
IdentityFile ~/.ssh/example_25519
User user
Port 23
Host jail.example.net
IdentityFile ~/.ssh/example_jail_25519
User deploy
Port 2323
| Command | Connection |
|---|---|
ssh one | user@one.local:22 |
ssh example.net | user@host.example.net:23 |
ssh whatever.example.net | user@host.example.net:23 |
ssh jail.example.net | deploy@host.example.net:2323 |
*
Host *
AddKeysToAgent yes
PreferredAuthentications publickey
VisualHostKey yes
AddKeysToAgent– Im ssh-agent die Keys halten.PreferredAuthentications publickey– Keys-First, Bedenken second!VisualHostKey– Spielzeug…
StrictHostKeyChecking
Wenn sich die Host-Keys ändern (Server wird installiert, System hat nur eine RAM-Disk)…
Host setup
StrictHostKeyChecking no
IdentityFile ~/.ssh/key_ed25519
Host 10.11.1.11
User rescue
Oder halt so:
ssh -o StrictHostKeyChecking=no -i ~/.ssh/key_ed25519 rescue@10.11.1.11
SSH Escape Sequences
Beim frickeln mit Plastikroutern und OpenWRT fiel mir was ein:
telnet lässt sich nach einem Abbruch der Verbindung (z.B. Neustart des
Routers) mittels
Control-[quit
sauber beenden.
Gibts das auch für ssh? Na klar!
Also was tun, wenn die SSH-Verbindung eingefroren ist? Man drückt:
[enter]~.
(Return, Tilde und Punkt, nacheinander.)
-
Eine Hilfe gibt es mittels:
[enter]~?
Diese verrät noch ein paar andere nützliche Dinge.
-
LogLevel ändern:
[enter]~V(== rauf)[enter]~v(== runter) -
Commandline (um dann Forwards einzurichten):
[enter]~C -
Die Forwards auflisten:
[enter]~# -
Background SSH (auf das Beenden der Verbindung warten):
[enter]~& -
Suspend SSH:
[enter]~Control-Z
Steht sogar in der manpage ssh(1) (unter “ESCAPE CHARACTERS”),
ist aber dennoch ein recht unbekanntes Feature von ssh.
unlocks.sh
Ganz einfach - in die ~/.ssh/config ganz unten einfach so was:
Host *
AddKeysToAgent yes
Der Eintrag in der ~/.ssh/config macht das Selbe und ist viel sauberer!
SSH Keychain komfortabel mit Schlüsseln vollschaufeln, ohne in Fehler zu
rennen Shell Script!!1!
#!/bin/sh
SSH_ADD=$(which "ssh-add")
SSH_KEY=$(which "ssh-keygen")
msg () { echo "$(basename "$0") | $*"; }
KEY_FILE="${KEY-"$1"}"
if [ -z "$KEY_FILE" ]; then
msg "specify key file, please."
exit 1
fi
msg "$KEY_FILE"
KEY_INFO=$($SSH_KEY -lf "$KEY_FILE" 2>&1)
KEY_CODE=$?
msg "$KEY_INFO"
if [ $KEY_CODE -ne 0 ]; then
msg "error" "[$KEY_CODE]"
exit $KEY_CODE
fi
KEY_HASH=$(echo "$KEY_INFO" | cut -d' ' -f2)
if $SSH_ADD -l | grep -q "$KEY_HASH"; then
msg "already unlocked."
exit 0
fi
$SSH_ADD "$KEY_FILE"
exit $?
- platformunabhängig
- posix
- verteiltes echtzeitjava
- zertifiziert
- banane
LPIC
Vor langer Zeit habe ich mal eine LPIC Schulung mitgemacht.
War gut, habe viel gelernt. Auf den Unterseiten die Aufzeichnungen von damals.
Bash Grundlagen
Prompt
Der Prompt ist frei konfigurierbar: $PS1:
Benutzer@Hostname: Verzeichnis Status
Interne/Externe Kommandos
type Kommando
-
Kommando is /bin/Kommando
Kommando ist extern
-
Kommando is a shell builtin
Kommando ist intern
Befehle aufrufen
Kommando -short --longOption [optionale Parameter]
ls -alman lsrm -rf /(Please do try this at home!)mkdir -p /tmp/wurst/wasser
$PATH
bestimmt die Suchpfade der Bash
-
Welche Pfade sind hinterlegt?
echo $PATH:[...]:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:[...] -
Bei gleichnamigen Programmen wird
$PATHsequentiell durchgesucht- Programm
progin/usr/sbin/und/sbin//usr/sbin/progwird ausgeführt!
- Programm
-
Neue Pfade werden in der
.bashrchinterlegt, eigene Shellskripte kommen nach/usr/local/binbzw./usr/local/sbin
Aliasse
-
ls -l als Standard (es lassen sich bestehende Kommandos überschreiben, vorsicht!):
alias ls='ls -l' -
ls ohne gesetzten Alias aufrufen:
'ls' \ls /bin/ls
Ausführen
prog1; prog2
Erst prog1 dann prog2:
prog1 & prog2
prog1 läuft im Hintergrund, parallel dazu prog2:
prog1 && prog2
prog2 wird nur ausgeführt, wenn prog1 erfolgreich war:
prog1 || prog2
prog2 wird nur ausgeführt, wenn prog1 nicht erfolgreich war (nicht
mit der Pipe verwechseln)
Wann war ein Programm erfolgreich? :
echo $?
$? == 0=> Erfolg!$? != 0=> Gefahr!
Hilfe suchen
Meistens funktioniert programm --help
Dann gibt es da noch den info Befehl (kenne aber keinen, der diesen
nutzt).
Wichtiger sind die man-Pages:
man-Pages zum Thema XY findet man mittels apropos XY
Innerhalb der man-Pages:
- Pfeiltasten oder PageUp/Down zum Navigieren
- Suchen mit
/ - Weitersuchen mit
n(oder rückwärts mitN) - Beenden mit
q
Achtung - die man-Pages haben mehrere Sektionen: man 1 passwd ist was
anderes als man 5 passwd!
Navigieren im Verzeichnisbaum
pwd (Print Working Directory) - Wo bin ich denn überhaupt?! (pwd -d
hilft bei Symlinks)
cd (Change Directory):
cd /etc - wechseln nach /etc cd - wechselt ins Home-Verzeichnis
(~) cd - - wechselt ins vorherige Verzeichnis (in diesem Fall nach
/etc)
pushd, popd, dirs (Arbeiten mit dem Stack):
pushd /etc - legt /etc auf den Stack, und wechselt nach /etc
popd - entfernt letztes Element vom Stack, und wechselt in den
vorherigen Ordner dirs - zeigt den momentanen Stack
Arbeiten mit Dateien
Kopieren: cp quelle ziel (es geht auch cp quelle1 quelle2 ziel)
Verschieben: mv quelle ziel (es geht auch mv quelle1 quelle2 ziel)
Löschen: rm datei
Verzeichnis löschen: rmdir verzeichnis (geht nur, wenn Verzeichnis
leer ist, ansonsten rm -rf verzeichnis)
Neue, leere Datei anlegen (oder Zeitstempel aktualisieren):
touch datei
Ordner anlegen: mkdir ordner (Verschachtelte Verzeichnisse lassen sich
mit mkdir -p ordner/unterordner anlegen - legt erst ordner an, dann
ordner/unterordner)
Informationen zu Datei anzeigen: file datei
Komprimieren/Zusammenfassen: tar (Tape-Archive)
- Anlegen:
tar cvf myarchive.tar /ordner(Anlegen und komprimieren:tar czvf myarchive.tar.gz /ordner) - Entpacken
tar xvf myarchive.tar(oder für komprimierte Archive:tar xzvf myarchive.tar.gz) - Archiv-Inhalt anzeigen lassen:
tar tvf myarchive.tar(oder für komprimierte Archive:tar tzvf myarchive.tar.gz)
History
Anzeigen: history
Letzten Befehl wiederholen: !!
Befehl #23 (vom Befehl history) wiederholen: !23
Befehl der mit bla beginnt wiederholen: !bla
History durchsuchen: CTRL+r
History löschen: history -c
Pipes
Die Ausgabe des einen Programms kann die Eingabe des nächsten Programms sein:
prog1 | prog2 | prog3
Standard-Kanäle
stdin (Kanal 0) - Eingabe, meist Tastatur (oder aus Pipe)
stdout (Kanal 1) - Ausgabe, meist das Terminal (oder in Datei, Nadeldrucker mit Endlospapier, whatever)
stderr (Kanal 2) - Fehlerausgabe
Umleiten
prog 1> file: stdout (Ausgabe) von prog wird in file
geschrieben
prog 2> file: stderr (Fehler) von prog wird in file
geschrieben
oder in Kombination: prog 1> outputfile 2> errorfile
Bash Grundlagen - Hausaufgabe
-
Ist das Kommando
[intern oder extern?:type [ >> [ is a shell builtin which [ >> [: shell built-in command -
Setze deinen Bash-Prompt, so dass er wiefolgt aussieht:
$Username $Uhrzeit(HH:MM:SS) >>:PS1='\u \t >> ' oder PS1='\u $(date +%H:%M:%S) >> ' -
Schreibe eine Kommandozeile, in der ein Verzeichnis angelegt wird. Wenn das Verzeichnis erfolgreich angelegt wurde, soll eine Meldung auf dem Bildschirm ausgegeben werden:
mkdir -p /tmp/my/folder && echo "eine Meldung" -
Lege die Ordnerstruktur /tmp/foo/bar/baz mit EINER Kommandozeile an. Entferne sie danach in einem Rutsch mit dem Kommando rmdir:
mkdir -p /tmp/my/folder && rmdir -p /tmp/my/folder -
Navigiere mit pushd in deinem System. Wechsel in das Verzeichnis /tmp, dann in /usr/share und dann in /lib. Wechsel nun zurück in /tmp:
pushd /tmp pushd /usr/share pushd /lib dirs >> /lib /usr/share /tmp ~ pushd +2 >> /tmp ~ /lib /usr/share -
Kopiere das Verzeichnis /usr/share/man in dein Homeverzeichnis. Lösche danach das kopierte Verzeichnis rekursiv:
mkdir ~/man && cp -rv /usr/share/man ~/man && rm -rf ~/man -
Was passiert bei folgenden Umleitungen?
-
kommando &>/tmp/foo- stdout & stderr: Console
-
kommando 1>&2 2>/tmp/foo- stdout & stderr:
/tmp/foo
- stdout & stderr:
-
kommando >/tmp/foo 2>>/tmp/foo- stdout: Console
- stderr:
/tmp/foo(anhängen)
-
Prozesse
- PID: Process ID
- PPID: Parent Process ID
- Benutzer
- Gruppe
- Priorität (nice)
- aktuelles Verzeichnis (pwd)
- Prozessumgebung
Linux macht prä-emtpives Multitasking
- runnable/running
- sleeping
- stopped
- zombie
Info über Prozesse
Laufende Prozesse legen Informationen im Proc-System ab:
/proc/PID
- siehe
man 5 proc
ps (Process Statistics)
-
ps -l -U nutzer- Alle Prozesse von Nutzer
-
ps --forestoderpstree- Prozessbaum mit Hierarchie
-
ps -ef --forest- Prozessbaum mit Abhängigkeiten
-
topoderhtop- Informationen in Echtzeit
Prozesse beeinflussen
-
kill&killall- siehe
man 7 signal
- siehe
-
kill -l- SIGHUP (Hangup) - auflegen
- SIGINT (Interrupt) - unterbrechen (
ctrl-c) - SIGKILL (Kill) - sofort beenden ohne aufräumen
- SIGTERM (Terminate) - beenden mit aufräumen
Prioritäten
Der Scheduler weist allen Prozessen Rechenzeit zu, über die sie verfügen
können. Das Verhältnis kann mit dem nice-Wert beeinflusst werden:
- von -20 (most favorable scheduling) bis +19 (least favorable scheduling)
- Standard: 0
Beim Start: nice Beim bereits laufenden Programm: renice
- siehe
man nice
Einschränken
z.B. Maximale Anzahl der geöffneten Dateien, Speicher, CPU-Zeit etc
ulimitulimit -a
Regular Expressions
| Grundlagen | |
|---|---|
c | Das Zeichen c |
[abc] | Das Zeichen a, b, oder c |
[a-c] | Alle Zeichen von a bis c |
[^abc] | Nicht a, b, oder c |
^ | Der Anfang einer Zeile |
$ | Das Ende einer Zeile |
. | Irgendein beliebiges Zeichen |
\* | Das vorherigie Zeichen wird beliebig oft wiederholt |
\
| Extras | |
|---|---|
\< | Anfang eines Wortes |
\> | Ende eines Wortes |
() | Gruppierung von Mustern |
(A|B) | Alternative: A oder B |
? | Optionaler Ausdruck |
\+ | Ausdruck kommt mind. 1 mal vor |
{min,max} | Anzahl der Wiederholungen |
\n | Rückbezug auf den n-ten RegExp in Klammern |
Helferlein/Beispiele
man 7 regex
Nicht verzweifeln - RegExr verwenden, der ist sehr gut!
-
Alle Varianten von Super, Supra, super, supra:
[Ss]up(er|ra) -
Drei mal das Muster n-mal alle Zeichen außer ‘:’ gefolgt von einem ‘:’. Am Ende eine 100:
([^:]*:){3}100 -
Die Damen und Herren namens Maier, Meier, Mayer, Meyer:
M[ae][iy]er -
Eine E-Mail Adresse:
[A-Za-z0-9._-]+@[A-Za-z0-9._-]+\.[A-Za-z]{2,4} -
Alle Zeilen die mit Frosch beginnen:
grep -e --color=auto '^Frosch' -
Alle Zeilen die mit drei beliebigen Zeichen beginnen, gefolgt von einem Leerzeichen:
grep -e --color=auto '^... ' -
Alle Zeilen, die nicht mit # beginnen:
grep -e '^#'
Textverarbeitung auf der Console
Anzeige von Dateien
cat & tac
-
Texte zusammenfassen:
cat file1.txt file2.txt file3.txt > file_compiled.txt -
Ausgabe mit Zeilennummern (
-n) und mit allen Steuerzeichen (-A: LF, CR, TAB, …):cat -n -A file.txt -
Ausgabe mit Zeilennummern ohne Leerzeilen (
-b), dabei doppelte Leerzeilen zusammenfassen (-s):cat -b -s file.txt -
tacistcatin rückwärts
Anfang und Ende von Dateien
head & tail
-
Die ersten und letzten 10 Zeilen:
head -n 10 file.txt tail -n 10 file.txt -
Die ersten 32 Kilobyte:
head -c32k file.txt -
Das Ende von
/var/log/messages, bleibt offen und aktualisert, sobald was neues geloggt wird:tail -f /var/log/messages -
Alle Zeilen ab Zeile 23:
tail -n +23 file.txt
Zeichen ersetzen
tr
-
Kleinbuchstaben durch Großbuchstaben ersetzen:
tr a-z A-Z < input > output -
Alle ‘Nichtbuchstaben’ durch Leerzeichen ersetzen:
tr -c A-Za-z ' ' < input > output -
Mehrere Leerzeilen zu einer zusammenfassen:
tr -s '\n' < input > output
Tabs/Spaces konvertieren
expand & unexpand
-
expand konvertiert Tabs zu Leerzeichen
-
unexpand konvertiert Leerzeichen zu Tabs
-
Konvertiere Tabs zu vier Leerzeichen:
expand -t 4 input > output
Strings abschneiden und formatieren
fmt & pr
-
Ausgabe ab Zeichen 45 Umbrechen:
fmt -w 42 file.txt -
Einrückungen am Zeilenanfang beibehalten (CrownMargin):
fmt -w 42 -c file.txt -
Spalten (-2) formatieren:
fmt -w 23 input.txt | pr -2 -o 3
Zeilen nummerieren und zählen
nl & wc
Zeilen nummerieren (per Default alle nichtleeren Zeilen):
nl -b a -i 10 -w 5 input.txt
nl -n rz -v 1000 quellcode.cpp
| nl | |
|---|---|
| -b | Bodyzeilen |
| -i | Increment (um 10) |
| -w | Breite der Nummernspalte |
| -n | rz Rechtsbündig |
| -v | Beginne mit Zeilennummer |
Anzahl der Zeilen der Ausgabe von ls – Sprich: Wieviele Dateien liegen in /home?:
ls /home | wc -l
Daten in Hex und Oktal
hexdump & od
-
Ocatal Dump:
od -txcz /etc/passwdod -td -An -N1 /dev/random -
Verbrennt die Hexe! Gib 64 Byte aus (
-n), zeige Zeichen (-C):hexdump -n 64 -C /bin/ls
Text abschneiden und verkleben
cut, paste & join
cut - Jedes Zeichen ist eine Spalte, Feldtrenner ist per default \t,
gibt Zeilen ohne Trennzeichen komplett aus.
-
Spalten 1-3,5,10 mit Trennzeichen
::cut -d: -f 1-3,5,10 file.txt
paste - klebt Daten Zeilenweise zusammen, Feldtrenner ist per default
\t
paste -s - Durchläuft die Dateien hintereinander
Alle Zeilen der ersten Datei werden in eine Zeile geschrieben, mit Tab separiert, dann das gleiche mit der nächsten Datei in die nächste Zeile
join - Daten relativ zusammenfüren
vereinigt 2 Dateien auf Basis eines Vereinigungsfeldes Vereinigungsfeld muss per Default das erste Feld einer Zeile sein:
join -t: -1 3 -2 5 file1.txt file2.txt
Text sortieren und aussortieren
sort & uniq
Default ist lektographisch nach ASCII (Abhängig von der Ländereinstellung der Console) Kann auch ‘Felder’ sortieren, der Feldtrenner ist dann im Default ein Leerzeichen
Lokale Nutzer nach Spalte 4 Sortieren:
sort -t: -k4,4 /etc/passswd
| sort | |
|---|---|
| -r | Absteigend sortieren (reverse) |
| -u | unique (Siehe unten, uniq) |
| -n | Nummerisch sortieren |
| -b | ignore leading blanks |
| -t | Trennzeichen |
| -k | Sortiere nach Feld (zwischen den Zeichen von ‘-t’) |
Doppelte Zeilen entfernen (Die Eingabe muss sortiert sein):
sort file.txt | uniq
sort -u file.txt
vi
Damals™, vor dem Krieg, gab es nur ed (Zeilenweise), die Tastaturen hatten keine extra Tasten (<100)
vi ist Bildschirmbasiert, und benötigt keine Sondertasten! Darüber hinaus ist vi bei (fast) jedem Linux mit dabei.
vi [optionen] file1 file2
programm | vi -
Modi
- Kommandomodus: Editor steuern, im Text navigieren
- Eingabemodus: Schreiben (Ein- und Angeben!!1!)
- Kommandozeilenmodus: längere Kommandos eingeben, Kommandos auf (markierten) Text anwenden
| Navigation | |
|---|---|
h | Ein Zeichen nach links |
l | Ein Zeichen nach rechts |
k | Ein Zeichen nach oben |
j | Ein Zeichen nach unten |
0 | Zeilenanfang |
$ | Zeilenende |
w | Wort vorwärts |
b | Wort zurück |
G | Zur letzten Zeile |
<n>G | Zur Zeile n |
f<c> | Zum nächsten Zeichen c |
Ctrl+f | Bildschirmseite vor |
Ctrl+b | Bildschirmseite zurück |
\
| Kommandos | |
|---|---|
a | Text hinter akt. Zeichen einfügen |
A | Text am Zeilenende einfügen |
i | Text vor akt. Zeichen einfügen |
I | Text am Zeilenanfang einfügen |
o | fügt eine Zeile unter der aktuellen Zeile ein |
O | fügt eine Zeile über der aktuellen Zeile ein |
x | löscht Zeichen hinter dem Cursor |
X | löscht Zeichen vor dem Cursor |
r<c> | ersetzt aktuelles Zeichen durch <c> |
dw | löscht Wort |
d$ | löscht bis Zeilenende |
d0 | löscht bis Zeilenanfang |
df<c> | löscht bis <c> |
dd | löscht ganze Zeile |
dG | löscht bis Ende des Texts |
d1G | löscht bis Anfang des Texts |
cw | Wort ersetzen |
c$ | Ab Cursor bis Zeilenende ersetzen |
c0 | Ab Cursor bis Zeilenanfang ersetzen |
cf <c> | Bis <c> ersetzen |
c/abc | Bis Muster abc ersetzen |
\
| Kommandozeile | |
|---|---|
:w [name] | speichert Puffer in Datei |
:w! [name] | speichert trotz Schreibschutz |
:e [name] | liest Datei in Puffer |
:r [name] | fügt Inhalt von Datei hinter akt. Zeile ein |
:! [cmd] | führt Shellkommando aus |
:r! [cmd] | fügt Ausgabe des Kommandos hinter aktueller Zeile ein |
:q | beendet vi |
:q! | beendet vi ohne Rückfrage |
:wq | speichern und beenden |
:x | speichern und beenden |
Prozesse, RegEx, Textverarbeitung, vi - Hausaufgabe
-
Arbeite
vimtutorbis Kapitel 5.3 durch -
Wieviele Benutzer haben
/bin/bashals Loginshell auf deinem System?:grep /bin/bash /etc/passwd grep /bin/bash /etc/passwd | wc -l -
Bereite die Ausgabe von
ls $HOMEfür den Druck vor. Die Auflistung soll in 3 Spalten dargestellt werden:ls ~ | pr -3 -
Lasse dir die ersten 30 Zeichen der Datei
/etc/issueanzeigen:head -c 30 /etc/issue -
Folge als Benutzer ‘root’ der Datei
/var/log/messages. Rufe dann parallel in einer anderen Shell folgendes Kommando auf:logger Hallo von der Kommandozeile:-
Alt+F1sudo tail -f /var/log/messages -
Alt+F2logger Hallo -
Alt+F1>> Mar 06 11:29:15 hostname user: Hallo
-
-
Lasse dir eine Textdatei mit allen darin enthaltenen Steuerzeichen anzeigen:
cat -Acat -vET -
Wieviele Zeilen enthält deine
/etc/inputrc?:c -l /etc/inputrc -
Sortiere die Datei
/etc/passwdnummerisch nach GruppenID (Spalte 4):sort -t : -n -k 4,4 /etc/passwd -
Filtere alle Zeilen aus der Datei
/etc/inittabaus, die mit einem ‘#’ beginnen (Kommentare). Wieviele Kommentarzeilen sind in der Datei enthalten?:grep -v '^#' /etc/inittab grep '^#' /etc/inittab | wc -l -
Was passiert bei folgender Kommandozeile und warum?
sed -e 's/foo/FOO/g' text.txt > text.txt-
Eigentlich sollte jedes ‘foo’ durch ‘FOO’ im Text ersetzt werden, jedoch ist die Umleitung falsch
- Resultat: leere test.txt
-
-
Wie könnte man trotzdem die Datei direkt editieren?
- mit
text.txt > neuertext.txtoder mitsed -i
- mit
Das Trennzeichen in sed kann auch anders gewählt werden:
sed -i -e 's//etc/issue//etc/foo/g' test.txt sed -i -e 's/etc/foo|g' test.txt
-
Lasse dir alle Dateien in
/usr/bin anzeigen, die mit einem ‘b’ beginnen, dann einen beliebigen Buchstaben enthalten, dann einmal ein ‘c’ bzw. kein ‘c’ enthalten:ls /usr/bin | grep ^b.c ls /usr/bin | grep ^b.[^c] -
Starte das Kommando
dd if=/dev/zero of=/dev/nullmit niedrigster Priorität. Schicke es nach dem Start in den Hintergrund (CTRL+z) und lasse es danach im Hintergrund weiterlaufen. Beende das Programm, indem du das ‘Terminate’ Signal an den Prozess schickst:nice -n 19 dd if=/dev/zero of=/dev/nullCTRL+z[1]+ Stopped nice -n 19 dd if=/dev/zero of=/dev/nullbg[1]+ nice -n 19 dd if=/dev/zero of=/dev/null &kill -9 %nice -
Starte den Editor ‘vi’. Schicke Ihn in den Hintergrund. Nun schau dir die Handbuchseite zum Befehl ‘df’ an:
viCTRL+zman df -
Schicke nun auch die Handbuchseite in den Hintergrund. Wechsele dann wieder zum Editor zurück:
CTRL+zfg 1 -
Warum ist das beenden eines Prozesses via
kill -9 $prozessmit Vorsicht zu genießen?- Offene Dateien werden nicht zu Ende geschrieben..
- Alle Unterprozesse von sterben mit (und werden Zombieprozesse)
-
Starte das Kommando
dd if=/dev/zero of=/dev/nullim Hintergrund. Lasse das Programm dann ‘netter’ zu den anderen sein, indem du dessen Nice-Wert auf 10 erhöhst:dd if=/dev/zero of=/dev/null & renice -n 10 2342 -
Darfst du den Nice-Wert eines Prozesses nach dessen Start erniedrigen?
- Normalerweise nicht
-
Was ist die höchste Priorität, die ein Prozess haben kann, wenn er von einem unpriviligierten User ausgeführt wird?
- je kleiner der Wert, umso weniger ‘nice’ ist der Prozess zu anderen…
- root darf von -20 bis 19
- user darf nur von 0 bis 19
- je kleiner der Wert, umso weniger ‘nice’ ist der Prozess zu anderen…
Der Bootprozess
Ablauf
- Power on
- BIOS POST
- BIOS Lädt die ersten 46 Byte
- Bootloader lädt das OS
- OS Lädt Treiber, stellt RootFS, und lädt init
- init startet Bootscript, Runlevelscripte, und getty (für login)
Bootloader
Grub - Grand Unified Bootloader
- komplex
- Kann Dateisystemzugriff
- Interaktive Shell
- (meist) Standard
- Konfiguration:
/boot/grub/menu.lst(Partition 1 auf 1. Festplatte:hd0,0)
Lilo - Linux Loader
- Kann keine Dateisysteme lesen (nur von Sektoren booten)
- Neue Config == Neue Installation
- Konfiguration:
/etc/lilo.conf
Kernelparameter
Geben dem System spezielle Optionen mit auf den Weg
init=Programm: Startet Programm anstatt /sbin/initrw/ro: Rootpartition mit/ohne Schreibrecht einhängenrunlevel: Gewünschtes Runlevelsingle: Einbenutzermodus/Rootmodus/Single-User-Modemem=groesse: max. RAM Benutzungmaxcpus: max. benutzbare CPUs
Init
kann sich nicht selbst killen - kill -9 ist nutzlos ;)
System-V-init => populär!!1!
Alternativen kommen so langsam:
- Upstart
- systemd
- minit/cinit
Runlevels bestimmen was für Dienste gestartet werden:
-
klassische Runlevels:
- 1/S: Single-User-Mode
- 2: Multiuser (ohne Netzwerk)
- 3: Multiuser mit Netzwerk
- 4: frei
- 5: Multiuser mit Netzwerk und GUI
- 0/6: System Halt/Reboot
- 7-9: frei-konfigurierbar
-
Bedarfs-Runlevel A,B,C - führen gewünschte Aktionen aus, ohne den aktuellen Runlevel zu ändern:
xy:ABC:ondemand:Aktion -
Konfiguration unter
/etc/inittab, Spaltentrennung durch:etikett:RUNLEVEL:Aktion-
etikett: frei wählbarer String
-
RUNLEVEL: In welchem Runlevel gilt die Aktion
-
Aktion:
respawn: Starte Prozess bei beenden neuwait: Starte Prozess einmal und warte aufs Endebootwait: Aktion wird beim Booten ausgefährt, Runlevel egalinitdefault: Welches Runlevel ist der Standardctrlaltdel: Was passiert bei diesen drei Tasten
-
-
Bootskripte (z.B. fsck, Uhrzeit setzen, mount, KernelModule laden..)
- Debian:
/etc/init.d/rcS - RedHat:
/etc/rc.d/init.d/boot - SuSE:
/etc/init.d/boot
- Debian:
-
init-skripte (Starten Dienste)
- Haben Parameter wie
start,stop,restart,reload, etc - Debian:
/etc/init.d/ - RedHat:
/etc/rc.d/init.d/ - Beispiel:
/etc/init.d/mailserver restart
- Haben Parameter wie
-
Runlevels konfigurieren (Einfach durch Symlinks!)
-
jedes Level hat einen eigenen Ordner:
- Debian:
/etc/rcN.d/(update-rc.d) - RedHat:
/etc/rc.d/rcN.d/(chkconfig) - SuSE:
/etc/init.d/rcN.d/(insserv)
- Debian:
-
jeder Symlink hat ein spezielles Format:
S/K: Dienst starten/beendenZahl: Reihenfolge
-
-
System neustarten:
init 6rebootctrl+alt+del
-
System ausschalten
init 0sync && haltshutdown -h nowshutdown -h 12:00 "Mittagspause"shutdown -cAbbruch vom momentanen shutdown.
Partitionen
partedgparted(grafisch)fdisk-
Beispiel: Neue Swap anlegen:
fdisk /dev/sdan (Neue Partition) p (Primäre Partition) 2 (Partitionsnummer) t (Partitionstyp) 82 (Linux Swap)
-
Bootprozess, init, Partitionen - Hausaufgabe
-
Installiere das Betriebssystem CentOS 6 (x86) in einer virtuellen Maschine
-
Warum ist die Erstellung einer dedizierten
/bootPartition von Vorteil?- Lilo, der nur Sektorweise booten kann, bekommt nicht seine Daten die er starten soll überschrieben
- Einfaches Dateisystem im Boot, kompliziere Dateisysteme auf den anderen Partitionen
- für verschlüsselte Festplatten
-
Welche anderen Hierarchien (Verzeichnisse) sollten auf eigenen Partitionen liegen?
| Verzeichnis | |
|---|---|
/ | System |
/boot | Boot |
swap | Swap |
/home | Benutzerordner |
/var | Alle Spools, alle Logs und so weiter |
/tmp | Wenns sein muss |
/usr | Keine Systemkritischen Programme (nur lesend einbinden -> Virenschutz) |
/etc | auf gar keinen Fall auslagern! (Wichtig fuer den Systemboot!) |
Alle weiteren Übungen werden in dieser virtuellen Maschine umgesetzt!
-
Starte das System im Single User Modus (Kernelparameter)
- In Grub1:
init=/bin/bash - In Grub2:
singleam Ende der Kernel Line
- In Grub1:
-
Du hast dein root-Kennwort vergessen und möchtest es zurücksetzen. Starte hierzu dein System so, das die normale Systeminitialisierung umgangen wird. (Kernelparameter)
- In Grub1:
init=/bin/bash - In Grub2:
singleam Ende der Kernel Line - dann mit
passwdneues Passwort setzen
- In Grub1:
-
In welchem Runlevel befindest du dich gerade?:
runlevel -
Wechsel in das Runlevel 1 und danach wieder in das ursprüngliche Runlevel:
init 1 && init 5 -
Ändere das Standard Runlevel auf 2:
-
in der
/etc/inittab:id:5:initdefault -
austauschen:
id:2:initdefault
-
-
Deaktiviere die Möglichkeit das System via CTRL+ALT+DEL neu zu starten
-
in der
/etc/inittab:ca:12345:ctrlaltdel:/sbin/shutdown -
austauschen:
ca:12345:ctrlaltdel:
-
-
Erstelle eine erweiterte Partition, die den gesamten verfügbaren Plattenplatz einnimmt:
fdisk /dev/sdb>> new extended partition -
Erstelle in dieser erweiterten Partition zwei 1GB grosse logische Partitionen:
>> new ~ 1GB -
Die Partitionen sollen ohne reboot sichtbar werden
- in
/etc/fstabeintragen;mount
- in
-
Erstelle in der ersten logischen Partition ein ext2 Dateisystem mit folgenden Eigenschaften:
-
10% reserviert fuer root:
mkfs.ext2 -m 10 /dev/sdb1 -
automatischer fsck nach 60 mount-Vorgängen:
tune2fs -c 60 /dev/sdb5 -
aktiviere nachträglich das Journaling auf dem ext2 Dateisystem:
tune2fs -j /dev/sdb5 -
Erstelle nun auf der 2ten logischen Partition ein ext4 Dateisystem:
mkfs.ext4 /dev/sdb6 -
Hänge nun jedes Dateisystem einmal im System unter /mnt ein. Erstelle jeweils eine Datei unter /mnt mit dem Namen der Partition:
mount /dev/sdb5 /mnt && touch /mnt/sdb5/file && umount /mnt/sdb5 mount /dev/sdb6 /mnt && touch /mnt/sdb6/file && umount /mnt/sdb6 -
Sorge dafür, dass beide logische Partitionen nach dem Systemstart im System eingehangen sind.
-
Die erste logische Partition soll im Verzeichnis /foo eingehangen werden.
-
Die zweite logische Partition soll im selben Verzeichnis eingehangen werden.
-
Was passiert nach dem Start des Systems?
- es wird die zuletzt eingehängte Partition angezeigt
-
-
-
Mit welchem Tools kann ich folgende Hardwareinfos einholen?
- angeschlossene USB-Geraete?
lsusb - eingebaute NIC?
ifconfig - RAM?
lshw - CPUs?
lscpu
- angeschlossene USB-Geraete?
-
Erstelle einen zusätzlichen Booteintrag in Grub, kopiere hierzu den ersten Eintrag der Konfigurationsdatei. Entferne den Parameter ‘quiet’ und ‘rhgb’, ändere den Titel in ‘Red Hat Classic’ und passe die globalen Konfigurationsparameter an.
Benutzer
Benutzer ‘Name’ anlegen:
useradd Name
| . | |
|---|---|
| -m | Homeverzeichnis |
| -s | Shell des Benutzers |
| -g | Primäre Gruppe |
| -G | sonstige Gruppen |
Benutzer ‘Name’ ändern:
usermod Name
| . | |
|---|---|
| -s | Shell ändern |
| -G | zusätzliche Gruppen ändern |
| -a | Gruppen anhängen, nicht ersetzen |
Benutzer ‘Name’ löschen:
userdel Name
| . | |
|---|---|
| -r | löscht neben dem Konto auch den Homefolder sowie den Mailspool |
Gruppen
Gruppe ‘Name’ anlegen:
groupadd Name
| . | |
|---|---|
| -g | Gruppen-ID festlegen |
Gruppe ‘Name’ ändern:
groupmod Name
| . | |
|---|---|
| -n | Neuer Name |
| -g | neue Gruppen-ID |
Gruppe ‘Name’ löschen:
groupdel Name
| . | |
|---|---|
| -n | Neuer Name |
| -g | neue Gruppen-ID |
Passwort
Passwort von ‘Name’ ändern:
passwd Name
| . | |
|---|---|
| -l | Zugang sperren |
| -u | Zugang entsperren |
| -m N | Passwortänderung höchstens alle N Tage |
| -x N | Passwortänderung nach spätestens N Tagen |
| -w | Warnfrist festlegen |
Ablauffrist des Passworts für ‘Name’ einstellen:
chage Name
| . | |
|---|---|
| -E Y-M-D | Ablaufdatum einstellen |
| -E -1 | Ablaufdatum aufheben |
| -l N | N-Tage Frist nach dem Ablaufdatum |
| -m N | Passwortänderung höchstens alle N Tage |
| -M N | Passwortänderung nach spätestens N Tagen |
| -W | Warnfrist festlegen |
Konfigurationsdateien
/etc/passwd- Lokale Benutzerdatenbank/etc/group- Lokale Gruppebdatenbank/etc/shadow- Lokale Passwortdatenbank/etc/default/useradd- Legt Standartwerte für neue Benutzer fest (Kann mituseradd -Dangezeigt und geändert werden)
Hardware
Alle angeschlossenen USB-Geräte anzeigen: lsusb
- Unterstützung
- OHCI = USB1.0 => Ab Kernel 2.0
- EHCI = USB2.0 => Ab Kernel 2.2
- XHCI = USB3.0 => Ab Kernel 2.6
Alle angeschlossenen PCI-Geräte anzeigen: lspci
-
lspci -n- Die Geräte nicht in der internen Datenbank nachschlagen, nur ausgeben als was sich die Geräte dem System gegenüber ausgeben - Gut zum Treiber suchen, Fehler beheben, etc.
-
lspci -k- Die (laufenden/möglichen) Kernelmodule zu den PCI-Geräten anzeigen
Generelle Hardware-Informationen anzeigen: lshw
/proc
-
Virtuelles Dateisystem mit dem Moutpoint
/procund FS-Typeproc -
Inhalt wird beim Aufruf erzeugt
-
jeder laufende Prozess hat einen Ordner mit seinem Prozessnamen:
ls /proc -
Zeige aktive Dateisysteme (nodev - Virtuelle Dateisysteme):
cat /proc/filesystems -
Zeige die Kommandozeile, mit der das System gestartet wurde:
cat /proc/cmdline -
Zeige Interrupts der Hardware:
cat /proc/interrupt -
Listet die Eingabe/Ausgabekanäle:
cat /proc/ioports -
Direct Memory Access - Zeige den Interrupt-Controller (Also Geräte die DMA für die einzelnen Devices bereitstellen):
cat /proc/dma
Systeminformationen aus dem BIOS lesen:
dmidecode
Hard- & Softlinks
Grundlagen
Jede Datei (die man sich per ls anzeigen lassen kann) ist eigentlich
nur ein Verweis auf einen Speicherbereich auf der Festplatte.
Wird eine Datei (innerhalb einer Partition) verschoben, wird nur der alte Verweis gelöscht, und ein neuer an der neuen Stelle auf den selben Speicherbereich angelegt. Die eigentlichen Daten bleiben unverändert.
- Symlink - Ist nur ein weiterer Verweis auf einen bestehenden Verweis
- Hardlink - Ist ein zweiter Verweis auf den selben Speicherbereich
Existiert kein Verweis mehr auf einen Speicherbereich, gilt die Datei als gelöscht.
Links anlegen
-
Hardlink:
ln quelle link -
Softlink:
ln -s quelle link
Links anzeigen
-
Hard- und Softlinks anzeigen:
ls -i -
Softlinks kann man schon auch schon so erkennen:
ls -l -
pwd- Zeigt im Standard nur den Symbolischen Pfad -
pwd -P- Zeigt den tatsächlichen Pfad
Suchen & Finden
find
- Durchsucht die Verzeichnishierarchie nach Dateien/Verzeichnissen
- Komplexe Filtermöglichkeiten
find <Verzeichnis> <Filter> <Begriff>
Suche in /home in allen Ordnern die dem User Hugo gehören alle Dateien, die mit .jpg enden:
find /home -user hugo -type f -iname "*.jpg"
Suche alle Dateien mit der exakten Größe von 10MB
(Größer als 10MB: +10M):
find / -size 10M -type f
Suche im aktuellen Verzeichnis alle Dateien, die neuer als ‘file’ sind:
find . -newer file
Suche in Home alle Dateien, die äter als 29 Tage sind, und lösche diese (mit Nachfrage):
find $HOME -atime +29 -exec rm -i '{}'\;
Suche im aktuellen Verzeichnis alle Ordner, die die Zeichenkette FOO enthalten (-a agiert als und; - verknüpft die Suchfilter):
find . \(-type d -a -name "*FOO*"\)
locate/slocate
-
Sucht Dateien in einem Index (wird mittels
updatedberstellt) -
Vorteil: schneller, da nur der Index durchsucht wird.
-
Nachteil: updatedb läft als root, indexiert also alle Dateien. Jeder User kann sich den vollen Index ansehen, dadurch auch den Inhalt fremder Home-Ordner..
-
Abhilde durch:
slocate -
Beispiele:
locate foo locate */bla.??? locate Projekte/Baumhaus
Finde ‘name’ in $PATH:
which name
Durchsuchte $PATH nach ‘name’, gibt deren Standardverzeichnisse, deren Manpages und alles, was mit ‘name’ noch zu tun hat aus:
whereis name
Hilfe zum Thema ‘name’ finden:
apropos name
Zugriffsrechte
chmod
Entferne das Ausführrecht für alle Benutzer für /tmp/foo:
chmod a-x /tmp/foo
cd /tmp/foo
>> bash: cd: /tmp/foo/: Permission denied
touch /tmp/foo/bar
>> touch: cannot touch `/tmp/foo/bar': Permission denied
ls /tmp/too
>> <Funktioniert!>
Verzeichnis ist also ‘festgebacken’ - User können sich den Inhalt anzeigen lassen, sonst aber nichts.
Man kann sich je nach Rechtevergabe relativ interessante Konfigurationen erstellen - Je nach Bedarf
-
Linux beachtet die Rechte in folgender Reihenfolge:
User vor Gruppe vor Rest
Ein Verzeichnis, dass deinem Benutzer keine Rechte einräumt, deiner Gruppe aber alle Rechte, kann von deinem Benuzter nicht verwendet werden, jedoch von einem anderen Nutzer deiner Gruppe.
Schreibrechte im Verzeichnis vorhanden? Jede Datei in dem Verzeichnis kann gelöscht werden, egal wem diese gehört, und wie dessen Rechte sind.
chown
Besitzer (und Gruppe) einer Datei festlegen:
chown Benutzer:Gruppe /Pfad/zur/Datei
chown -R => Rekursiv für alle Unterdateien
chown :Gruppe => Nur die Gruppe festlegen
chgrp
Gruppe einer Datei festlegen:
chgrp Gruppe /Pfad/zur/Datei
| Aktion | Buchstabe | Oktal |
|---|---|---|
| Lesen | r | 4 |
| Schreiben | w | 2 |
| Ausführen | x | 1 |
Sticky-Bit
-
Auf Verzeichnisse: Nur Besitzer und Root dürfen Dateien löschen (Bsp: /tmp)
-
Auf Dateien: möglich, wird aber i.d.R. ignoriert
ls -ld /tmp/
drwxrwxrwt 15 root root 4096 2011-12-03 12:29 /tmp/
Verzeichnis hat das Sticky-Bit gesetzt.
Ist das t groß, dann ist das Ausführen-Flag (x) nicht gesetzt.
-
SUID
- Programm wird immer im Kontext des Besitzers ausgeführt (Bsp: passwd)
-
SGID
- Programm wird immer im Kontext der Gruppe ausgeführt
ls -ld /usr/bin/passwd
-rwsr-xr-x 1 root root 42824 2011-06-24 11:28 /usr/bin/passwd
passwd kann von jedem Ausgeführt werden, läuft aber immer als root!
Ist das S groß, dann ist das Ausführen Flag (x) nicht gesetzt.
| Aktion | Buchstabe | Oktal |
|---|---|---|
| SUID | s | 4 |
| SGID | s | 2 |
| Sticky-Bit | t | 1 |
umask
Legt fest, welche Rechte für neue Dateien gesetzt werden sollen Berechnet sich durch NAND():
666 - 022 = 644
umask 053:
666 - 053 = 613
touch demo
ls -l
>> -rw--w-r-- ~blafasel~ demo
Stimmt nicht ganz
mkdir test
ls -l
>> drwx-wSr-- ~blafasel~ test
Scheint doch zu stimmen
- Diese Verwirrung ist ein Sicherheitsfeature™
- Bitte in der Wikipedia nachlesen
Man kann umask auch mit lustigen Argumenten aufrufen:
umask -S u+rwu=rwx,g=,o=umask -pumask 0077umask -S u+rw,g=ru=rwx,g=r,o=umask -pumask 0037
Benutzer, Hardware, Links, Suchen, Zugriffsrechte - Hausaufgabe
-
Finde über dmidecode Informaionen ueber dein BIOS.
- Es sollen nur Infos über das BIOS ausgegeben werden
-
Lasse dir deine PCI-Geräte anzeigen und finde heraus, welcher Treiber jeweils benutzt wird.
-
Erzwinge einen fsck zum nächsten Neustart.
-
Installiere und konfiguriere Lilo
- Starte das System mit Lilo und installiere dann Grub2.
-
Lege mit touch eine Datei
/tmp/dateian.- Lege einen symbolischen Link
/tmp/softlinkan, der auf/tmp/dateizeigt. - Nun lege einen Hardlink an, der auch auf die Datei zeigt.
- Lösche nun
/tmp/datei. Was passiert und warum?
- Lege einen symbolischen Link
-
Kopiere als root die Datei
/etc/shadowmittelscp -ain das Heimverzeichnis deines Benutzers.- Was darfst du als User mit der Datei machen?
-
Suche mit
findalle Dateien, die dem User ‘root’ gehören und das Setuid-Bit gesetzt haben. -
Was für eine Bedeutung hat das Setuid-Bit in diesem Zusammenhang?
-
Konfiguriere dein System so, das alle neu angelegten Dateien nur von deinem User gelesen und geschrieben werden können.
Bibliotheken
-
Bibliotheken bündeln Funktionalität
- n Programme, eine Bibliothek
- lässt sich leichter aktualisieren
-
Namenskonvention - Beispiel:
/lib/libfuse.so.2.8.5lubfuse.so- Name (so== shared object)2- Major Version8- Minor Version5- Patchlevel
-
Statisches/Dynamisches Linken
-
Dynamisch: Linken beim Programmstart (Schlanke Programme)
-
Statisch: Bibliotheken werden beim Compilieren reingelinkt
- Geschwindigkeitsvorteil, Kompatibilitätsvorteil, aber dann auch fette Binaries
-
-
ldd- Zeigt Abhängigkeiten von einem Programm zur Bibliothek an:ldd /usr/bin/top linux-vdso.so.1 => //Lib == Kernel libproc-3.2.8.so => /lib/libproc-3.2.8.so libncurses.so.5 => /lib/libncurses.so.5 libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 libtinfo.so.5 => /lib/libtinfo.so.5 /lib64/ld-linux-x86-64.so.2 //zum Starten von top -
Bibliothek verschoben, neue Bibliothek testen, oder mehrere Bibliotheken auf der Platte?!
-
Variable setzen:
export LD_LIBRARY_PATH=/home/meine/tollen/libs -
Oder dauerhaft/statisch festlegen:
echo /home/meine/tollen/libs >> /etc/ld.so.conf ldconfig
(
ldconfigerneuert den Library Cache) -